1. 对象管理-映射表管理菜单使用手册
1.1. 映射表基本概念
1.1.1. 什么是映射
Mixiot中数据采集和对象数据是分开的。一个对象的数据采集可以使用一个数据采集终端;一个复杂对象的数据采集,可以同时使用多个数据采集终端。同样,一个数据采集终端,也可以同时采集多个对象的数据。
一个数据采集终端一次采集的全部数据,称为一个栅格(Grid);一个栅格就像一个棋盘,棋盘的每个格子中是采集的实际数据。比如温度(K1)、压力(K2)、频率(K3)、电流(K4)、电压(K5)等,其中K1、K2、K3、K4、K5叫做栅格的键(Key)。
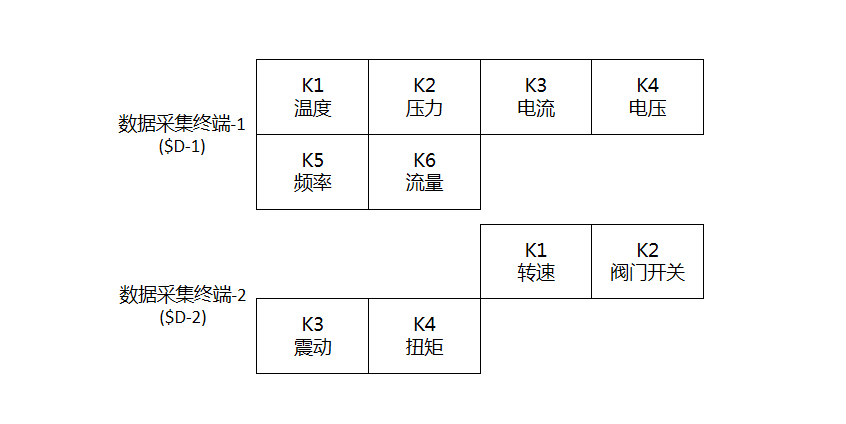
映射表的作用就是把不同的采集数据拼接到一起,变成对象的一个完整数据。其中,拼接后的数据X1、X2、X3...称为对象的柔性变量(Flexible Varible,简称FV)。
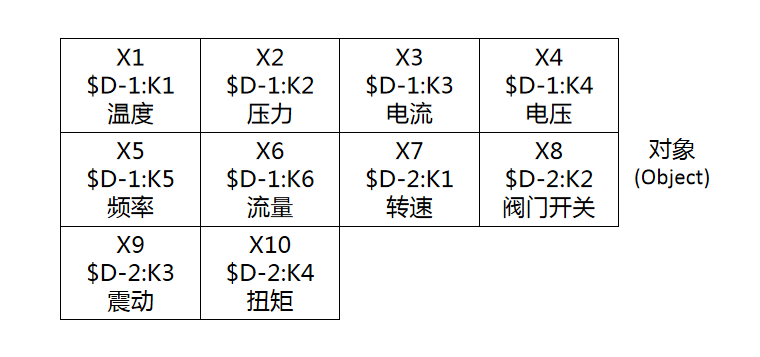
对象拼接后的数据叫做“马赛克(Mosaic)”,马赛克与栅格之间的对应关系可以表示为:
X1 = $D-1:K1
X2 = $D-1:K2
X3 = $D-1:K3
X4 = $D-1:K4
X5 = $D-1:K5
X6 = $D-1:K6
X7 = $D-2:K1
X8 = $D-2:K2
X9 = $D-2:K3
X10 = $D-2:K4
1.1.2. 什么是同步计算映射
Mixiot映射不仅仅是数据的直接拼接,还可以同步计算拼接。假设一个机电设备,K1,K2分别是机电设备的电流和电压;因为这个设备的阻抗在随时在变化,所以采集的电流和电压在一直变化。此时需要知道阻抗的数据以分析它们之间的关系,则可以多配置一个阻抗变量(X11);其中组态变量等于电压除以电流。
X1 = $D-1:K1
X2 = $D-1:K2
X11 = X2/X1
1.1.3. 什么是条件事件
Mixiot映射有一种特殊的情况,映射不是拼接数据,而是发布一个事件消息。假设一个锅炉设备,K1是采集的温度数据。当温度大于1000℃时,表示锅炉存在异常、需要进行报警;此时可以配置一个事件类型的FV变量,当满足条件时则发送事件消息。
1.1.4. 什么是同步外源映射
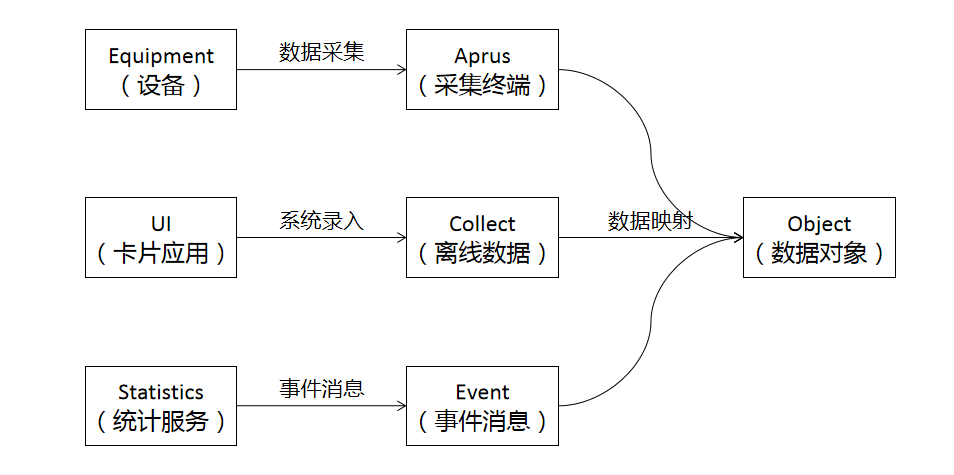
Mixiot是开放的事件驱动的实时系统,映射拼接的数据来源不仅仅是数据终端采集的在线数据,也可以是卡片应用(或API接口)录入的离线数据,还可以是系统服务产生的事件数据(比如统计计算结果、数据分析结果等)。
1.2. 映射表脚本规范
在Mixiot中通过“映射表”表示映射关系,映射表是一个Json格式的脚本。
1.2.1. 脚本规则
一行映射表的格式如下:
[`FV/Code`, `LabelEn`, `LabelLocal`, `Category`, `Channel`, `Key`, `LogicExpr1`, `LogicExpr2`, `PublicParams`]
- 第一列
数据拼接时第一列称为FV(即Flexible Varible,柔性变量), 是对象数据映射后的马赛克变量名(如“S01”为电流);
FV一般是不超过64个字符的字符串(要用双引号括起来),FV命名不能以$1,$2,$3,$4,$5为后缀结尾。因为mosaic的FV为五层缓存结构,在表达式中如果要因为某一层的FV进行计算或比较,需要用FV名+$1的形式,如S01$1,其中$1表示最上面那层(也就是最近一次的FV数据),$5表示最低下那层(即最旧的一层);
当表达式中引用某一层的FV,需要加上中括号[],如"[S01$1]+1"的形式;
发布事件时第一列称为Code(事件编码),是发布事件消息的统一编码(如"C1001"为开始生产事件,"C1002"为结束结束事件);Code也是不超过64个字符的字符串(要用双引号括起来)。当第八列(逻辑表达式2)满足条件时,会按照Code发布事件消息;
在一个映射表脚本中,定义的FV/Code需要是唯一的。
- 第二列
LabelEn为英文标签,主要对FV/Code用英文进行描述
- 第三列
LabelLocal为本地(中文)标签,主要对FV/Code用本地(中文)语言进行描述
- 第四列
Category为映射类型,分为STA, AGT, EVNT三类映射类型。
其中,STA是采集终端或者离线数据采集的数据进行拼接、AGT类型是订阅事件消息的数据进行拼接;EVNT为发布事件消息,当第八列(逻辑表达式2)满足条件时,生成事件给历程处理。
- 第五列
Channel为数据来源,分为终端编号、离线标识和事件消息条件。
当第四列Category为STA,填写终端编号或离线标识,表示从某个终端或某个离线采集数据。其中,Channel可以填写实际的编号(比如AX20211104001、COL114113310001);也可以填写宏变量$AprusID-index或$CollectID-index(index为数字索引),比如:$AprusID-1表示对象关联适配器列表的第一个适配器, $CollectID-2表示对象关联离线列表的第二个离线数据, 拼接时映射表会自动进行宏变量替换为实际的编号;
当第四列Category为AGT时, 填写订阅事件消息条件,格式为{"key":"val"}。其中,key:value是订阅事件的过滤条件,映射表会根据这些条件去订阅事件;比如:{uid":"STATISTICS1395846800006","block":"statistics","event":"statistics_result","object_id":"OBJ202110100001"},表示订阅统计编号为STATISTICS1395846800006、对象编号为OBJ202110100001的统计结果。其中,object_id的值也可以写成宏变量的方式$ObjectID-index,比如:$ObjectID-1表示对象子对象列表的第一个对象。特别地,$ObjectID-0表示对象本身编号。
- 第六列
Key为数据键名,比如L1_2_3、Temp、data。当Category为STA, EVNT时,与第五列对应填写采集终端上报的key后离线数据采集的key;当Category为AGT时,填写订阅事件消息返回值的键名。其中,事件消息时键名可以写成多层key的形式,如key1.key2.key3
- 第七列
LogicExpr1为逻辑表达式1,主要用于值计算,当第四列Category为映射类型为STA或AGT、且不是直接拼接而是需要计算后拼接情形填写。比如:min(S01,S02),表示取S01和S02中较小的一个拼接。
- 第八列
LogicExpr2为逻辑表达式2,主要用于判断是否生成事件,当第四列Category为映射类型为EVNT时填写。比如:S01>100,表示S01大于100时发布事件消息,小于等于100则不发布。
- 第九列
PublicParams为公共参数,配置FV变量的一些特殊属性,包括FV过期时间(expire_time)、FV默认值(default_value)等。本列为Josn格式,比如{"expire_time": "1m5s", "default_value": 1},表示FV过期时间是1分钟又5秒(65秒)、同时该FV默认值为 1
FV过期时间65秒的含义是,65秒内该FV都没上报拼接,则该FV将被清空
FV默认值为1的含义是,当FV初始化时还没有上报拼接数据、又需要使用该FV进行逻辑表达式计算,则使用默认值进行计算
1.2.2. 脚本示例
下列脚本定义了 v1、v2、v3、v4、v5、v6、v7、v8、v9等9个马赛克变量和1001、1002、1003等3个事件消息。
[
["v1", "", "终端采集-宏变量方式", "STA", "$AprusID-1", "L1_3_7_2", "", "", {"expire_time": "1m5s", "default_value": 1}],
["v2", "", "终端采集-宏变量方式", "STA", "$AprusID-1", "L1_3_7_2", "v1+10", "", {"expire_time": "1m5s", "default_value": 1}],
["v3", "", "终端采集-固定适配器", "STA", "AX20210229000249", "L1_3_7_2", "v2+10", "", {"expire_time": "1m5s", "default_value": 1}],
["v4", "", "离线数据-宏变量方式", "STA", "$CollectID-1", "Tem", "", "", {"expire_time": "1m5s", "default_value": 1}],
["v5", "", "离线数据-固定离线编号", "STA", "COL12236500002", "Tem", "", "", {"expire_time": "1m5s", "default_value": 1}],
["v6", "", "统计结果-事件消息", "AGT", {"uid":"STATISTICS1395846800006","block":"statistics","event":"statistics_result"}, "data", "", "", {"expire_time": "1m5s", "default_value": 1}],
["v7", "", "Indass分析结果-事件消息", "AGT", {"uid":"index1001","block":"indass","event":"indass_result"}, "index_change_accelerate", "", "", {"expire_time": "1m5s", "default_value": 1}],
["v8", "", "函数计算", "STA", "$AprusID-1", "L1_3_7_2", "min(v1, v2)", "", {"expire_time": "1m5s", "default_value": 1}],
["v9", "", "比较运算", "STA", "$AprusID-1", "L1_3_7_2", "v1>v2?v1:v2", "", {"expire_time": "1m5s", "default_value": 1}],
["1001", "start event", "开始事件", "EVNT", "$AprusID-1", "L1_3_7_2", "", "v1==0", {}],
["1002", "stop event", "停止事件", "EVNT", "$AprusID-1", "L1_3_7_2", "", "v1==1", {}],
["1003", "stop event", "停止事件", "EVNT", "$AprusID-1", "L1_3_7_2", "", "[v1$5]==1", {}]
]
注意:针对以上映射表脚本第一列fv命名中包含-短横线的情况,需要用[]来对命名进行转义,如["v-1"]的情况
1.2.3. 表达式
逻辑表达式1 与 逻辑表达式2 的语法规则是一样的,只是应用场景有所不同。逻辑表达式1一般是计算表达式,用于计算结果;逻辑表达式2一般是布尔表达式,用于判断条件是否成立。
- 运算符
| 优先级 | 分类 | 运算符 |
|---|---|---|
| 1 | 逻辑或 | || |
| 2 | 逻辑与 | && |
| 3 | 相等/不等 | ==、!= |
| 4 | 关系运算符 | <、<=、>、>= |
| 5 | 加法/减法 | +、- |
| 6 | 乘法/除法/取余 | *(乘号)、/、% |
| 7 | 布尔取反 | ! |
| 8 | 三目运算符 | 表达式?值1:值2 |
注意:优先级值越大,表示优先级越高,如果因为运算符导致计算结果又偏差,可以使用 () 来规范表达式优先级
1.2.4. 函数
| 函数名 | 函数说明 |
|---|---|
| min | 取最小值,如min(1, 2) |
| max | 取最大值,如max(1, 2) |
| abs | 取绝对值,如abs(-1) |
注意:函数内参数一般都是整数或浮点数,非特殊情况,不要填入字符串,以免造成计算错误或其他不可预知的问题
1.2.5. 参数说明
逻辑表达式由运算符、函数和参数组成,其中参数是已定义的FV变量,FV变量支持5层数据。假设一个变量为S01,则最新的第一层数据为[S01$1],次新的第二层数据为[S01$2]...,最旧的第5层数据为[S01$5];特别地,最新的一层[S01$1]一般直接写自身S01。
1.2.6. 拼接顺序
假设定义了两个FV变量v1和V2
[
["v1", "", "终端采集-宏变量方式", "STA", "AX2021110400001", "L1_3_7_2", "", "", {"expire_time": "1m5s", "default_value": 1}],
["v2", "", "终端采集-宏变量方式", "STA", "AX2021110400001", "L1_3_7_2", "v1+10", "", {"expire_time": "1m5s", "default_value": 1}]
]
变量v1是直接拼接的方式,在适配器AX2021110400001上报L1_3_7_2数据时则进行拼接。
变量V2是计算拼接的方式,当v1拼接完成后、自动计算 v1加10的结果进行拼接。
特别地,v2中填写的适配器AX2021110400001和键L1_3_7_2数据上报时也会触发计算;为保持数据一致一般与v1填写的一致,或者填写一个不存在的键(不会根据上报触发拼接,只根据v1联动触发拼接)
1.3. 映射表配置
映射表的配置需要在“对象管理”的“映射表菜单”中进行,支持映射表的添加、编辑、删除、查看映射表详情。映射表是对采集的设备数据的进行预处理形成一条完整的数据。映射表的配置通常与设备类型保持一致,即一类设备通常可以共用同一个映射表。比如工厂中有多台空压机,这些空压机型号是相同的、是同一个厂商的,所以他们的数据地址位是一样的,参数也是一样的,我们就可以为这个型号的空压机添加一个映射表,所有这个型号的空压机绑定这个映射表后,都能实现数据的处理,就跟同样型号的设备共用同一个说明书一个含义。
映射表的配置在“对象管理”应用的“映射表菜单”,支持对映射表进行添加、编辑、删除、查看映射表详情
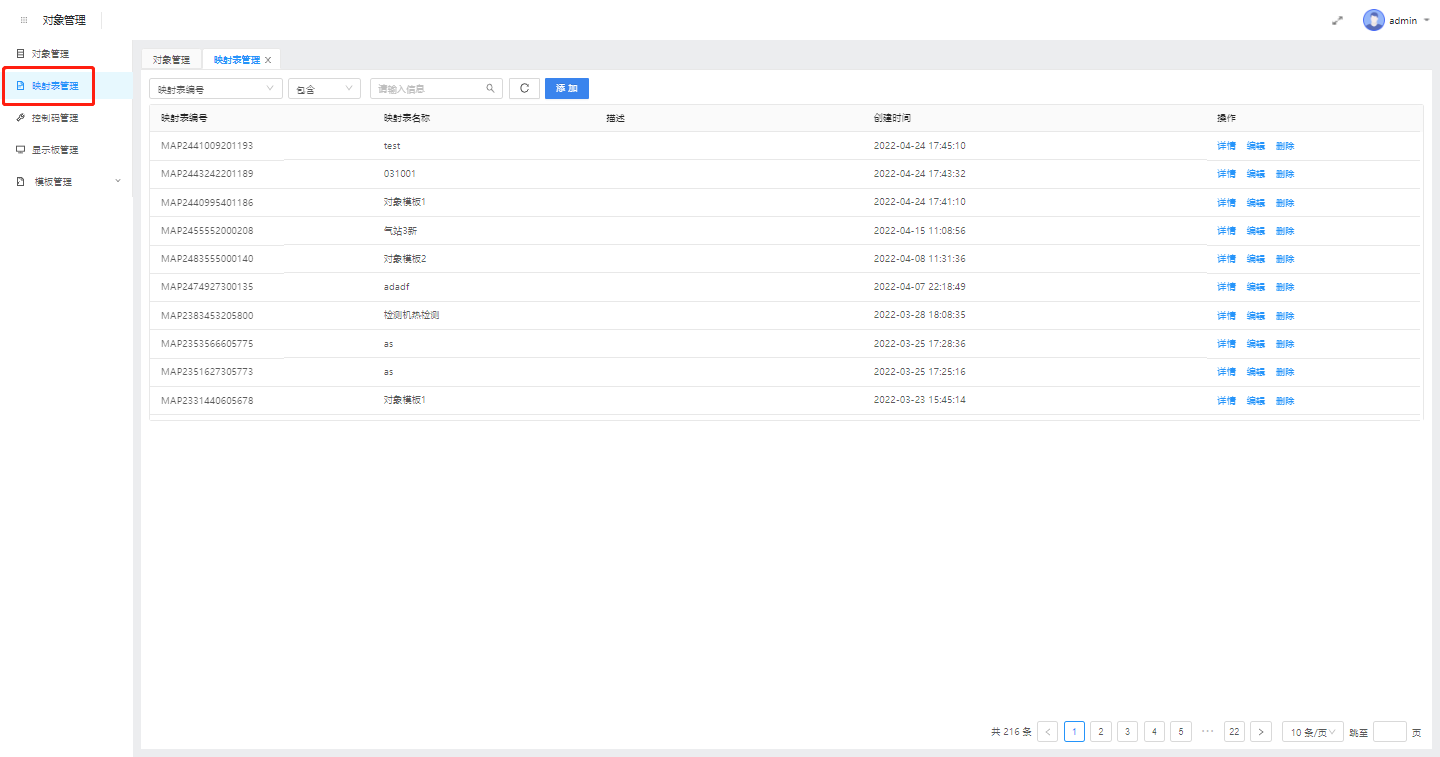
1.3.1. 映射表的添加和编辑
1.点击“添加”或“编辑”按钮,添加新的映射表信息或对现有映射表信息进行编辑更新
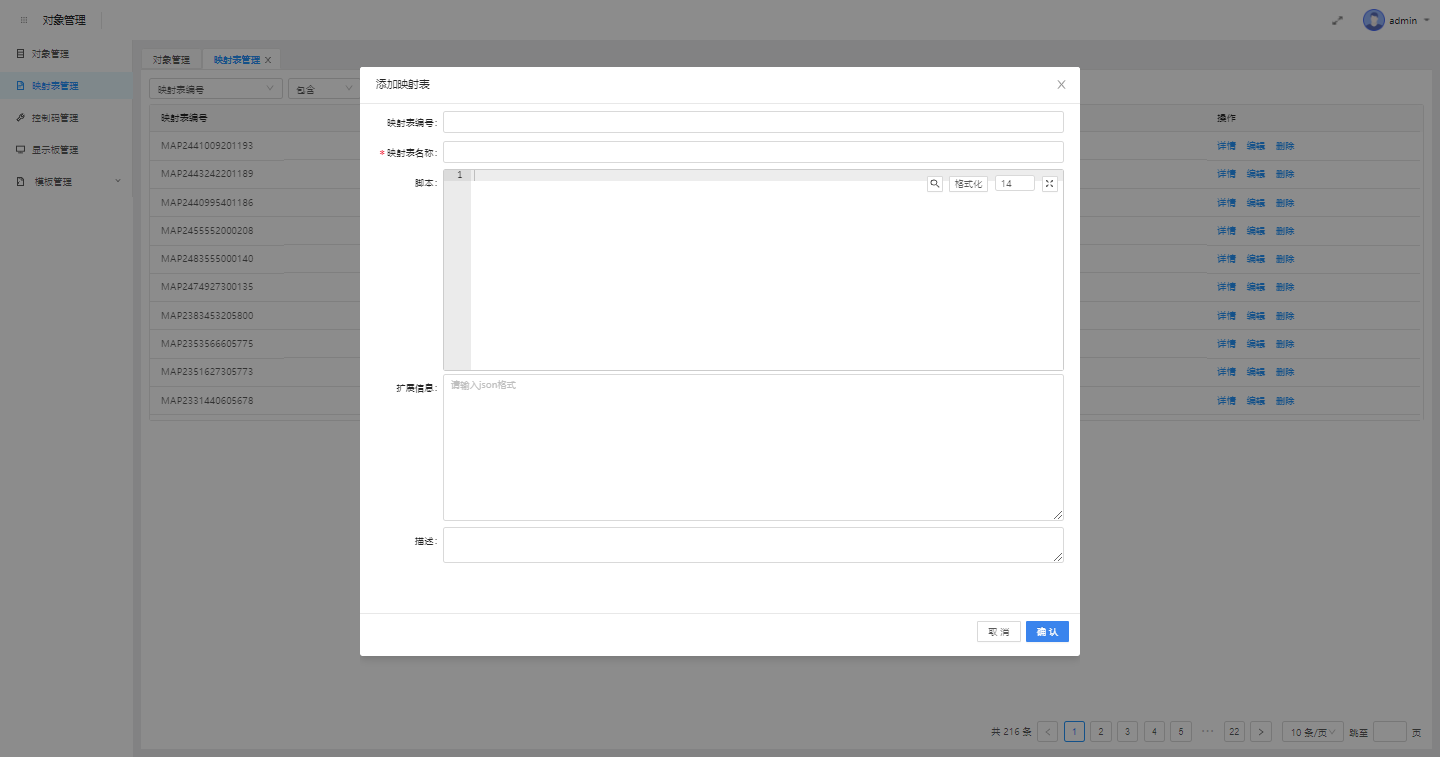
2.映射表字段说明
映射表编号:映射表在本系统的唯一标识,可自定义也可系统自动生成
映射表名称:自定义
脚本:根据本文档“映射表规范”整理的出的脚本
扩展字段:使用该映射表的设备需要扩展的其他字段信息,如合同编号、 国家其他排放标准等,配置后,可在“对象详情进行编辑和展示”
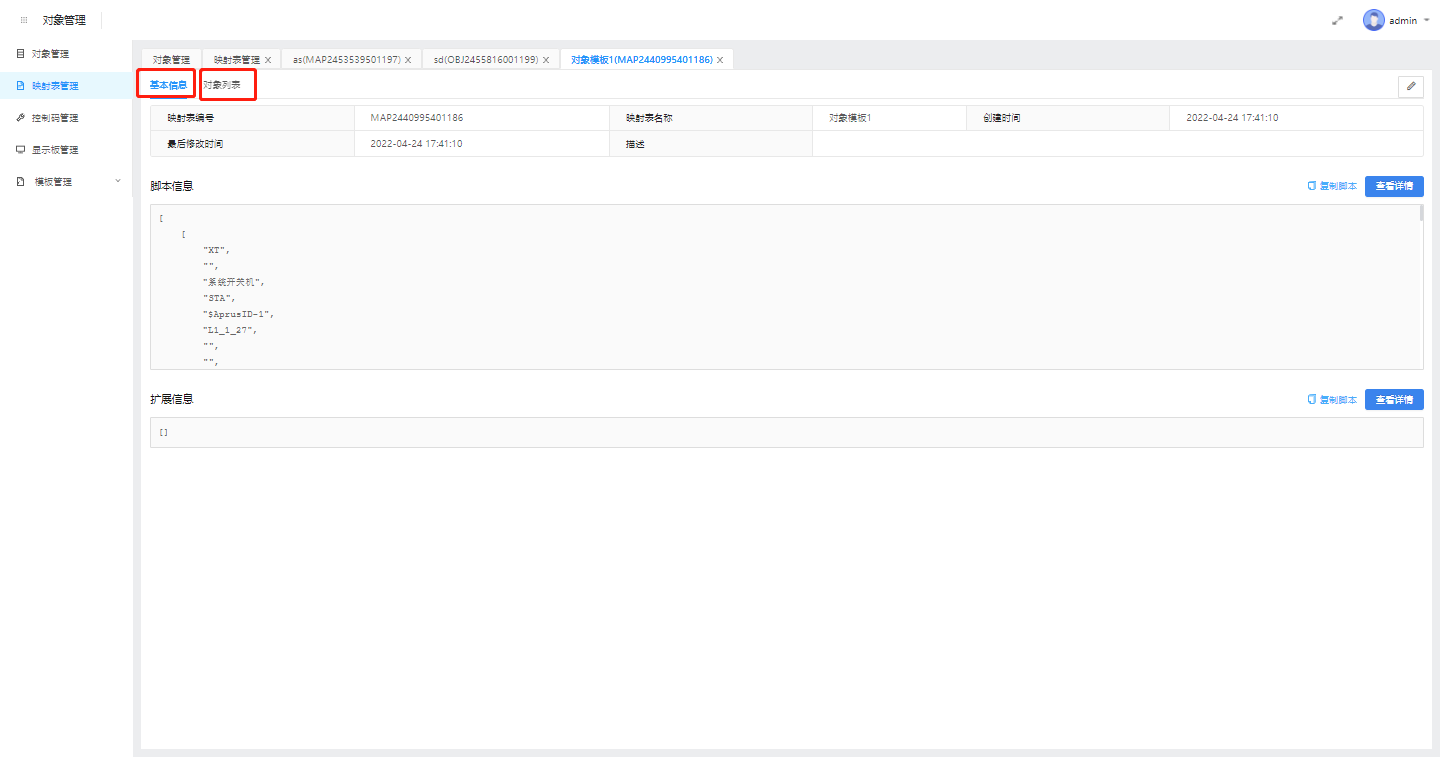
1.3.2. 映射表详情
点击“详情”即可查看所选映射表的详细信息,共包含两个标签页:基本信息、对象列表
1.基本信息
可查看映射表的脚本信息、扩展字段信息
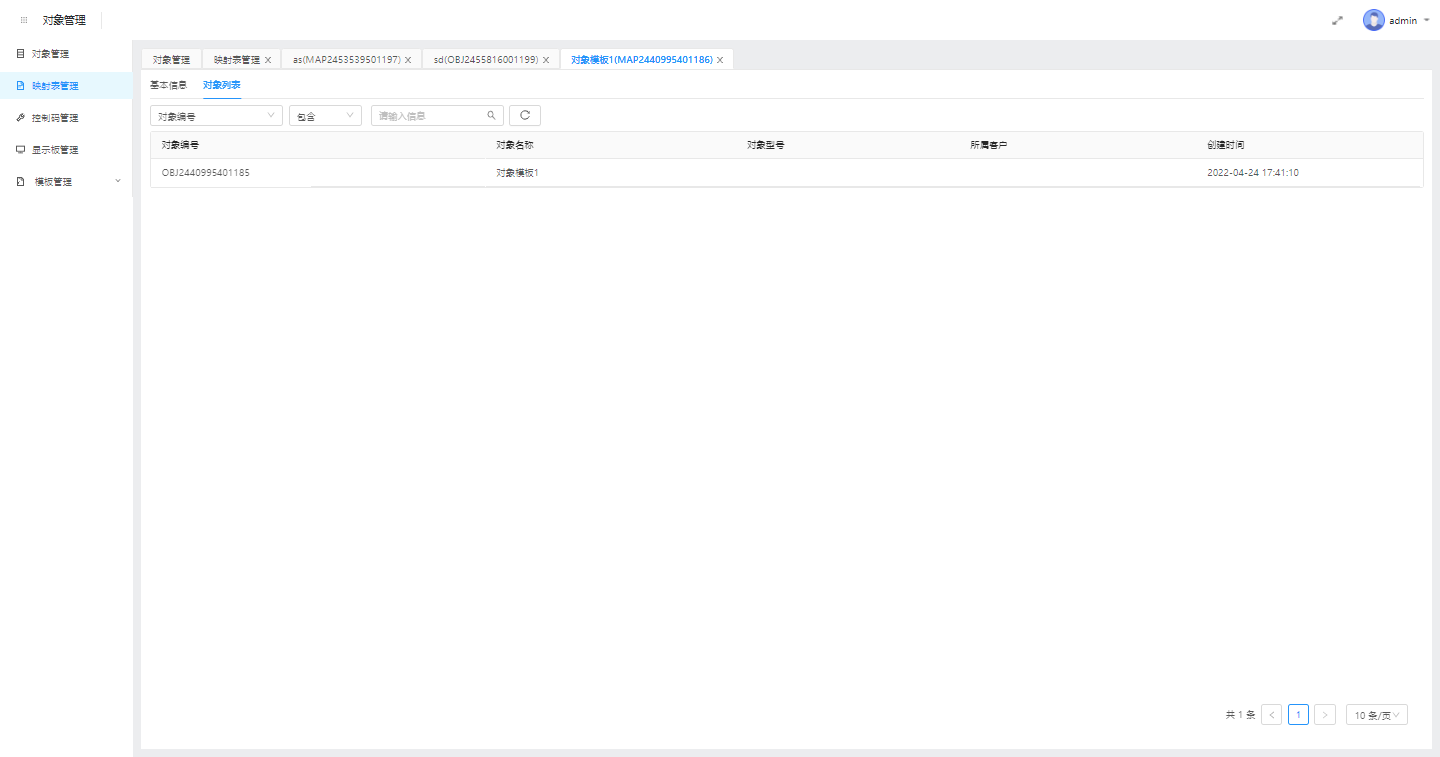
2.对象列表
可查看使用该映射表的设备具体有哪些,了解编辑或删除映射表会影响到哪些设备的数据展示
1.4. 映射表配置场景举例
本文档“映射表脚本规范”一节详细介绍了映射表的规则及每一列的含义,本节以实际场景为例,介绍一些实际的需求在映射表中如何配置。
假设我们目前有一台生产设备,主要有温度、压力、湿度、产量、转速等几个参数,已经用适配器完成了采集,并写好了对应的映射表脚本,我们基于此脚本,进行更多映射表配置的举例
[
["v1", "", "温度", "STA", "$AprusID-1", "L1_3_7_2", "", "", {}],
["v2", "", "压力", "STA", "$AprusID-1", "L1_3_7_3", "", "", {}],
["v3", "", "湿度", "STA", "$AprusID-1", "L1_3_7_4", "", "", {}],
["v4", "", "产量", "STA", "$AprusID-1", "L1_3_7_5", "", "", {}],
["v5", "", "转速", "STA", "$AprusID-1", "L1_3_7_6", "", "", {}],
["v6", "", "电流", "STA", "$AprusID-1", "L1_3_7_7", "", "", {}],
]
1.4.1. 根据设备参数判断设备开关机
1.设备的开关机如果能直接采集到是最好的,如果采集不到,就需要通过别的参数去判断,比如有的设备可以按转速大于0判断设备开机,有的设备可以按电流大于10判断设备开机,他的配置如下:
[
["v5", "", "转速", "STA", "$AprusID-1", "L1_3_7_6", "", "", {}],
["Z", "", "设备运行状态", "STA", "$AprusID-1", "L1_3_7_5", "v5>0?1:0", "", {}]
]
Z为新引入的一个参数,该参数的值不是由采集得到,而是由对其他的参数判断得到,v5>0?1:0,
“?”前面为判断条件,条件有两个结果:成立或者不成立,
“?”后面为对应判断结果的值,成立的话,则Z为“:”前面的数字,不成立的话,则“Z”为“:”后面的值
此处的含义为:v5的值是否大于0?如果大于0,则Z的值为1,否则Z的值为0
2.此处的判断条件比较简单,也可以是复杂的条件,比如设备开机的条件需要转速大于0且电流大于10,则后面表达式的写法如下:
[
["v5", "", "转速", "STA", "$AprusID-1", "L1_3_7_6", "", "", {}],
["v6", "", "电流", "STA", "$AprusID-1", "L1_3_7_7", "", "", {}],
["Z", "", "设备运行状态", "STA", "$AprusID-1", "L1_3_7_5", "v5>0&v6>10?1:0", "", {}]
]
可以看到“?”前面的表达式变成了v5>0&v6>10,即“&”为且的意思
3.如果转速大于0或者电流大于10都表示开机,二者并不需要同时满足,则表达式的写法需要换成下面这一种
[
["v5", "", "转速", "STA", "$AprusID-1", "L1_3_7_6", "", "", {}],
["v6", "", "电流", "STA", "$AprusID-1", "L1_3_7_7", "", "", {}],
["Z", "", "设备运行状态", "STA", "$AprusID-1", "L1_3_7_5", "v5>0||v6>10?1:0", "", {}]
]
“?”前面的表达式变成了v5>0||v6>10,即“||”为或的意思
4.以上为比较简单的两个状态的判断表达式,但实际中,设备的一个参数不同的值可以对应设备的更多状态,如转速大于0小于1000表示设备低速运行,转速大于等于1000小于1500表示设备高速运行,转速大于等于1500表示设备故障,此时就对应了设备的3个状态,这个需求的脚本写法如下
[
["v5", "", "转速", "STA", "$AprusID-1", "L1_3_7_6", "", "", {}],
["Z", "", "设备运行状态", "STA", "$AprusID-1", "L1_3_7_5", "(v5>0&v5<1000)?1:(v5>=1000&v5<1500?2:(v5>=1500?3:0))", "", {}]
]
该表达式即表明若v5在0-1000之间,Z的值为1,v5在1000-1500之间,Z的值为2,v5大于500时,Z的值为3,其他情况,Z为0
即:条件表达式1?值1:(条件表达式2?值2:(条件表达式3?值3:值4))
根据实际情况可进行更多层的表达式嵌套
上述4个场景即为条件表达式在实际场景中的应用,可参考完成自身需求的配置
1.4.2. 参数之间的计算
映射表支持一些基本的数学运算,如加减乘除,比如锅炉有实际压力,也有目标压力,想了解锅炉实际压力与目标压力之间的差值,这个需要用实际压力-目标压力才能得到,这个需求可直接在映射表进行配置
[
["v2", "", "实际压力", "STA", "$AprusID-1", "L1_3_7_3", "", "", {}],
["v7", "", "目标压力", "STA", "$AprusID-1", "L1_3_7_31", "", "", {}],
["v72", "", "压力差", "STA", "$AprusID-1", "L1_3_7_31", "v2-v7", "", {}]
]
v72为新引入的参数,该参数的值是由v2-v7得到,其他运算类似,根据需求配置即可
1.4.3. 映射表精度配置
设备采集或计算的数据偶尔有很多小数位,比如温度采集到的为27.09230943,不利于展示和分析,此时要对其进度进行设置,比如保留2位小数,配置如下:
[
["v1", "", "温度", "STA", "$AprusID-1", "L1_3_7_2", "", "", {"precision": 2}]
]
{"precision": 2}即表示保留2位小数,保留整数则为{"precision": 0}
1.4.4. 参数的自累加功能
比如设备每生产完一批产品,都会上报一下本批次的产量,但这个仅仅是每批次的,想知道设备生产的所有批次的产品的总和,比如第一批次生产500件,第二批次450件,第三批次650件,截止到目前一共生产了1600件,总产量的配置如下
[
["v4", "", "产量", "STA", "$AprusID-1", "L1_3_7_5", "", "", {}],
["v44", "", "产量累计", "STA", "$AprusID-1", "L1_3_7_5", "", "", {"accumulate": true}]
]
{"accumulate": true}即表示要对“L1_3_7_5”这个地址位上报的数据进行累加
1.4.5. 映射表计算参数环比
仍以设备产量为例,设备每生产完一批次的产品,都会上报一次产量,想了解批次产量的环比即:(本批次产量-上批次产量)/上批次产量×100,如果取到上个批次的产量呢,参考下述配置
[
["v4", "", "产量", "STA", "$AprusID-1", "L1_3_7_5", "", "", {}],
["v45", "", "产量环比", "STA", "$AprusID-1", "L1_3_7_5", "(v4-[v4$2])/[v4&2]*100", "", {}]
]
(v4-[v4$2])/[v4&2]*100该表达式即为环比计算表达式,与(本批次产量-上批次产量)/上批次产量×100对应,
则[v4$2]表示上个批次的产量,这里应用了映射表的缓存机制,即可以取到某个参数过去时刻的历史值,[v4$2]表示去v4上个时刻的,[v4$3]则表示取上上个时刻的历史值,最多至此到[v4$5],即往前数第5个历史时刻的值。注:缓存的历史数据,在编辑映射表后,会清空,影响初期的计算结果
1.4.6. 映射表获取统计实时结果
我们在mixiot系统配置了统计项目,比如统计设备的日耗电量,每天晚上12点整出昨天的总耗电量。配置的项目如下如所示
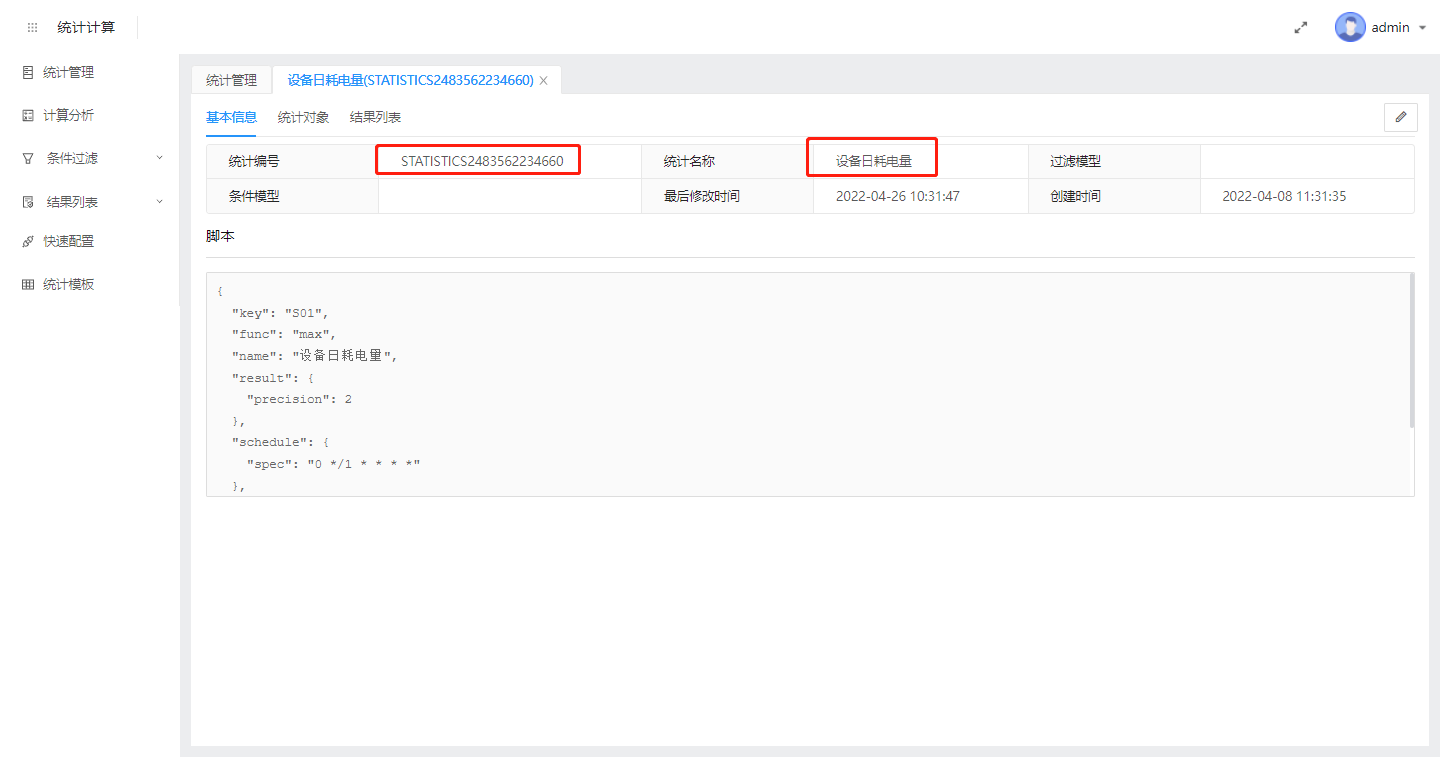
统计项目的特性是到设定周期会出周期结果,但因设备在不停运作,统计项目也同时会有一个实时的统计结果,比如早上10点半查看,这个实时结果是统计的晚上0点到10点半的统计结果,这个实时结果可以通过映射表配置获取到,和设备普通参数一起作为历史数据存放,便于分析和展示,映射表配置如下:
[
["v66", "", "耗电量实时统计结果", "AGT", {
"uid": "STATISTICS1395846800006",
"block": "statistics",
"event": "statistics_realtime_result"
}, "data.data", "", "", {}]
]
v66即耗电量统计的实时值,设备电表数据有更新,v66的值就会有更新,与普通参数配置的区别如下:
1.第四列,普通采集参数为“STA”,获取统计数据时,该参数为“AGT”
2.第五列,普通采集参数为“$AprusID-num”,即适配器序号,获取统计数据时,为一个{}
uid:统计项目编号,参考上图第一个红框,要获取哪个统计的实时数据,写哪个统计项目的编号
block:固定填写“statistics”
event:固定填写“statistics_realtime_result”
3.第6列,普通采集参数为对应的地址为,获取统计数据时,固定填写“data.data”
1.4.7. 映射表获取统计周期结果
上部分介绍了映射表获取统计实时结果,也可以获取统计的周期结果,映射表配置如下:
[
["v67", "", "耗电量实时统计结果", "AGT", {
"uid": "STATISTICS1395846800006",
"block": "statistics",
"event": "statistics_result"
}, "data", "", "", {}]
]
v67即耗电量统计的周期值,统计项目到期出本周期的结果,如每小时、每天、每月等,v67也会随着更新,与普通参数配置的区别如下:
1.第四列,普通采集参数为“STA”,获取统计数据时,该参数为“AGT”
2.第五列,普通采集参数为“$AprusID-num”,即适配器序号,获取统计数据时,为一个{}
uid:统计项目编号,参考上图第一个红框,要获取哪个统计的周期结果,写哪个统计项目的编号
block:固定填写“statistics”
event:固定填写“statistics_result”
3.第6列,普通采集参数为对应的地址为,获取统计数据时,固定填写“data”
1.4.8. 参数过期时间设置
设备上报的数据经映射表处理后,一般用于大屏、APP、PC端的显示板展示,如果设备因断电、停止生产等原因,没有数据上报时,这些显示板或默认展示最后的一条历史数据,这样的情况再去看显示板,各参数是有数据展示的,容易产生误解,这种问题可以通过设置参数过期时间的方式实现,配置如下:
[
["v4", "", "产量", "STA", "$AprusID-1", "L1_3_7_5", "", "", {"expire_time": "60s"}]
]
{"expire_time": "60s"}即为设置的过期时间,表示该参数如果60秒都没有上报,则会进行清空,清空后,该参数的历史数据自清空时刻开始为空,显示板显示也为空。注:“30m”,表示过期时间为30分钟,“2h”表示过期时间为2小时,根据实际情况设置即可。
1.4.9. 参数默认值设置
前面介绍过映射表的参数计算功能(4.2),也介绍过参数过期时间设置功能(4.8),如果一个参数(S01)设置了过期时间,且参与了另一个参数(S03)的运算,就会出现S01清空了,S03也没办法得到计算结果的情况,这种情况可以通过给参数设置默认值来解决,配置如下:
[
["v2", "", "实际压力", "STA", "$AprusID-1", "L1_3_7_3", "", "", {"expire_time": "60s", "default_value": 0}],
["v7", "", "目标压力", "STA", "$AprusID-1", "L1_3_7_31", "", "", {"expire_time": "60s","default_value": 2}],
["v72", "", "压力差", "STA", "$AprusID-1", "L1_3_7_31", "v2-v7", "", {}]
]
v2和v7均设置了过期时间,如果这两个参数中的任意一个超过过期时间没有上报,则会被清空,v72=v2-v7就没办法进行计算,但上述例子,v2和v7分别设置了默认值"default_value": 0,"default_value": 1,及v2如果参与计算时被清空了,则用0去计算,v7如果参与计算时被清空了,则用1去计算。特殊例子,v2和v7都清空了,v72=v2-v7=0-1=-1。
这就是参数默认值的用法,该默认值只在参数参与计算时使用,不作为参数本身的默认值在显示板展示。