风险分析计算
使用手册
[TOC]
简介
INDASS 里面说的 “风险” 是指状态的 “突变”。所以,INDASS 的风险分析,准确的说,应该是 “非机理突变风险预测”。什么是”非机理“呢,就是不管分析对象是锅炉,还是压缩机、发动机,我们抛开设备的机理、原理,只考虑他们的数据变化,这里的风险,特指具体的爆炸,崩塌,断裂,…,之类这些很具体的事情;那么什么是突变呢?突变就是指,应该对象的某些属性在变化过程中,在某⼀个瞬间出现的非连续变化特征。
我们还是举个例⼦,比如你买了个气球,这个气球说明书写的明明白白,气球的最大直径30公分。请问,你吹到30公分,或者超过30公分,气球⼀定会爆炸吗?再请问,你不吹到30公分,气球就⼀定不会爆炸吗?同理,压力容器上写着最大压力10kg/cm3,并不代表超过这个压力就会爆炸,更不代表低于这个压力就⼀定不爆炸,这里面相互影响的因素太多,各种因素变化导致的积累下来的原因,都会导致各种意外风险的发生。
INDASS 风险分析是按另⼀种模型来计算的,叫风险针模型,也可以叫蒲丰投针。这个模型是最符合非机理突变分析的情况,所以,应该会有比较准确的风险预测结果。⼀个对象也可以构建多个风险项目,每个项目可以有个针对性,也就是风险项目都是 “出现XXX风险”,算出来的结果是 “现在出现XXX风险的概率有多大”。
风险项目的设计,也是⼀个技术活儿,需要掌握⼀个粒度。如果粒度太大,即便算出来风险的概率大,也最多个警示,其实你也不知道这个风险是啥。如果风险粒度太小,可靠性就会降低。
其实在INDASS里面,“风险” 这个概念跟我们理解的风险是不⼀样的。INDASS风险的本质是:当前状态(这根针)接近、达到、或刺破某个特定边界(气球皮)的可能性有多大。
换一个角度来说,如果我们把某个好的、我们要追求的极限当做这个气球皮,那这个 “风险” 就不是我们常说的风险了,而是⼀个能不能达到最好极限的概率了。例如原来是30%的概率有风险,现在就是到达目标极限的概率是30%。
基本概念
我们说的某设备的风险,其实是某个风险项目。一个对象,可以进行多个风险项目的分析,这是因为一个对象事实上可能存在不同的风险,我们就需要对不同的风险进行分别研究,比如说温度风险分析、震动风险分析等等,根据风险对象每个侧面的重点,建立不同的风险项目。
在物联网里面,风险对象,就是我们面对的设备、工厂、生产装置,我们也可以理解为是Mixiot的对象。
风险项目,就是我们研究对象的风险,举一个比较好理解的例子,比如,风险对象是XXX同学。我们可以建立一些关于这个同学的风险项目,比如,项目 A1,上下班安全风险。这个风险的对象,就是XXX同学。请注意,XXX同学是研究对象,我们是没有办法说,XXX同学的风险。所以,我们说的风险,一定是一个很具体的风险项目。
那么,XXX同学每天要上下班,上下班路上(从出家门开始,到进公司),我们要研究的是这个风险。这样,这个风险项目就很清楚了。
在风险研究里面,说 “现在时刻”,那就是现在这个时间点,几点几分几秒,但是,如果说的 “现在”,那就是以现在这个时刻所在的时间段。比如,我们5分钟为一个风险周期,那么“现在”,那就是五分钟前到现在这个时间段; “将来”,那就是从现在开始算,往后五分钟内”, “过去”,那就是 “现在” 这个时间段以前的所有时间段。
威胁,就是设备在运行中,可能会遇到的与这个风险项目有对应关系,相关联的威胁。继续用上文说到的同学的例子,完整的概念就是:
风险对象:XXX同学
风险项目A:上下班步行风险项目
威胁B1:过马路交通意外;
威胁B2:走在路上被人劫财劫色;
威胁B3:走在路上被人拐骗
那么如何衡量将来的风险概率呢?首先就要根据具体的威胁,选择相关的参数,如果一个威胁相关的参数没有采集,那么这个风险项目是无法分析的。其次,还要知道相关参数的风险阈值,风险阈值有最大值和最小值,可以考虑到风险的两个界限。
补充一下,在实际建立项目的时候,表示威胁只要用不同的名字替代即可。可以用B1、B2、B3,也可以叫A1、A2、A3,或者X、Y、Z等等。
我们分析计算的风险结果,是一个概率,就是未来时间段会发生风险的可能性多大,但是在我们研究风险分析的时候,一个很重要的前提,就是我们要了解之前的风险分析的可能性有多大,也就是说,我们做未来的风险研究的前提,是知道之前这些威胁发生的条件概率。
条件概率的定义,我们见简单引用一下网上的资料,就是指事件A在另外一个事件B已经发生条件下的发生概率,数学表达式就是

就是这个同学在过马路时发生了交通意外的前提下,上下班步行时发生了风险的概率。
这个条件概率,我们可以用实验数据计算,也可以从文献里面寻找,或者通过历史数据计算,最差的情况,拍拍脑袋,当做0.5,有一半的可能发生,有一半的可能不发生。但是,我们一定要有一个这样的基础,在后面的计算中进行更新迭代,做分析计算。
得出了结果之后,如何衡量风险数值的大小,也是需要参考历史数据,并根据项目的分析逐步更新的。比如说,得出了风险概率是0.5,这个风险,是属于什么程度的风险呢?这就需要我们定义风险区间。
这个图的含义是,相应概率结果与设备状态的对应关系。这个值,也是从历史数据或者实际经验值等已有的结果提供的。如果一开始拿不定注意,那么也可以先拍脑袋指定[0,0.2,0.4,0.6,0.8,1],运行一段时间后看看。
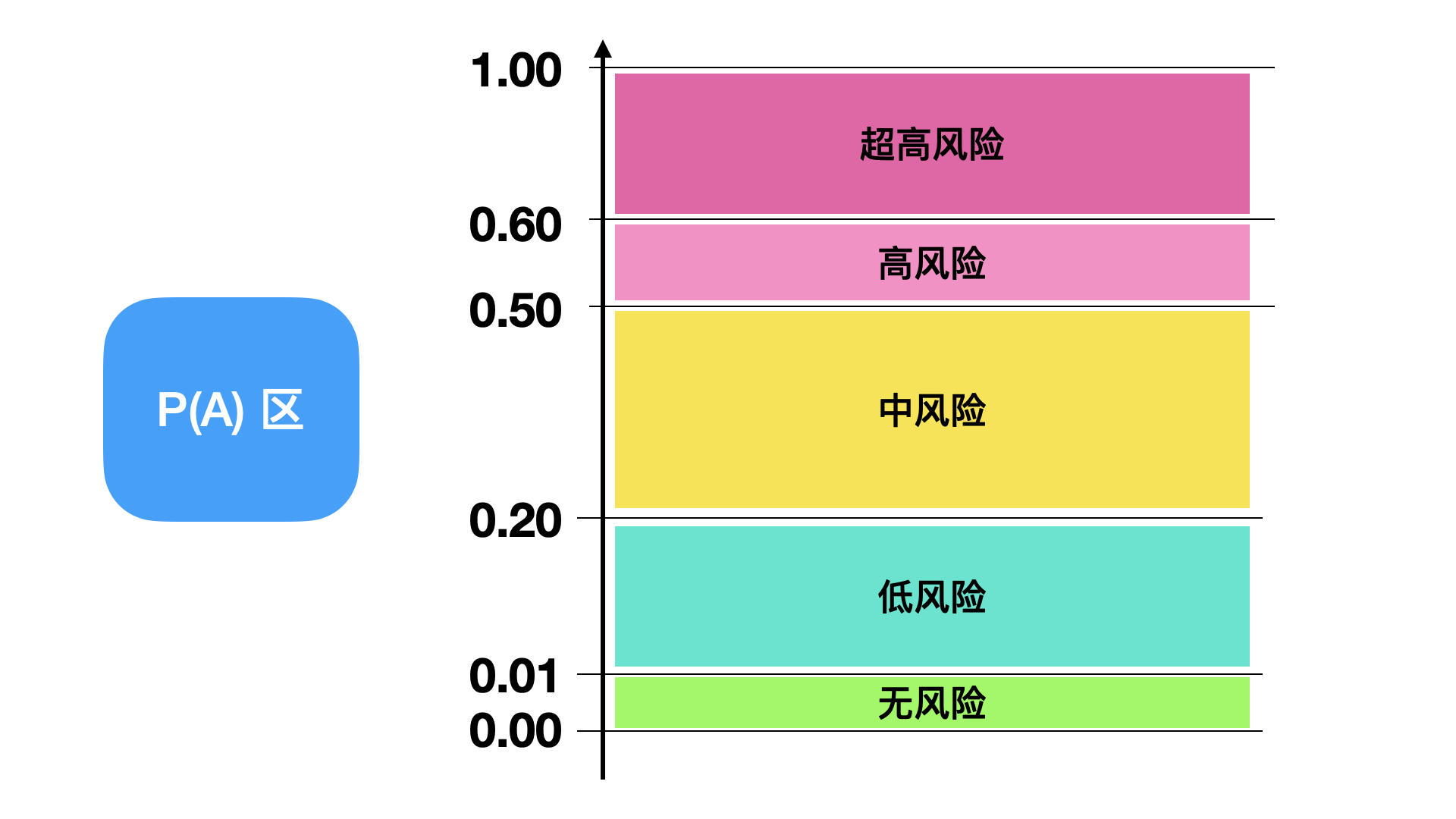
在有了这个基础上,我们就可以判断,当前的概率是处于中风险和高风险之间。
结果解释
在配置好了项目以后,风险分析项目会输出一个蒲丰投针图的结果数据,同时还有下周期到各个风险区块可能的概率。
接下来我们展示一下如何解读蒲丰投针模型。
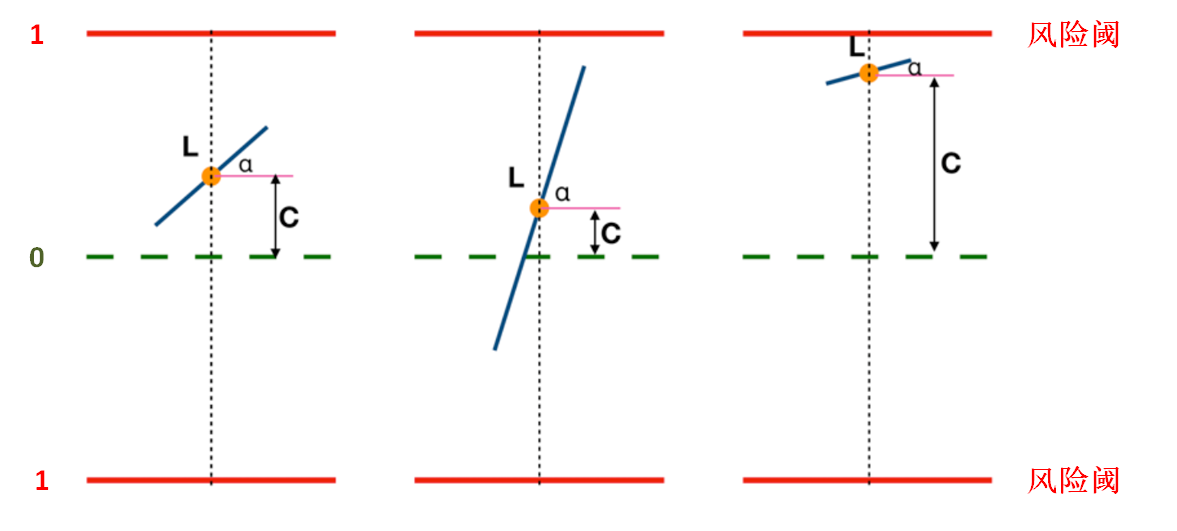
图中的风险线是1,当蓝色的针触碰到风险线的时候,就是风险非常可能发生的情况。图中的蓝色的针,就是蒲丰投针中的“针”,经过分析,我们注重的也是这个针在两个风险阈之间所处的位置。
针的长度,就是现在风险可能发生的概率,也就是图中L的长度;针上的黄色的点,就是历史的最低风险阈值,也就是C的长度,另外,针的与水平线的之间的夹角α,就是当前实际运行状态中,实际受到的关联作用和影响,如果角度越接近直角,那么针靠近风险线的速度就越快,产生风险的可能就越高。
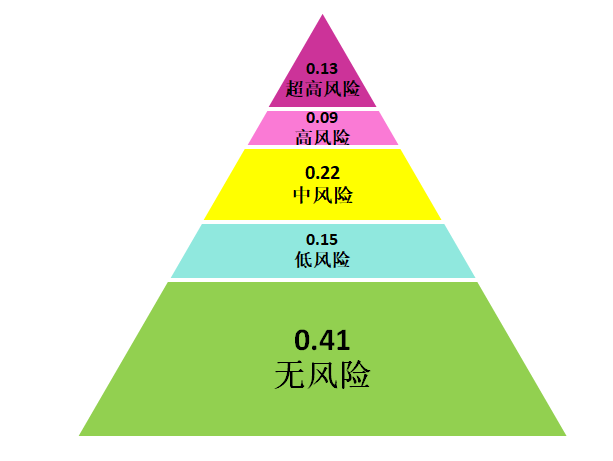
风险分析的输出结果,还有一组马尔科夫链,马尔科夫链具体的定义我们就不介绍了,它在我们风险分析的输出结果中的含义是:下一个周期可能到达的风险概率。
举个例子,某个项目输出的下周期风险概率为:[0.41, 0.15, 0.22, 0.09, 0.13],如下图,含义就是,从当前的状态(不管是什么状态)推测,下一期转到无风险概率是41%,跳转到低风险的概率是15%,跳转到中风险的概率是22%.... 等等以此类推。
界面说明
风险分析计算一共有3个界面,接下来我们分别展示:
项目管理
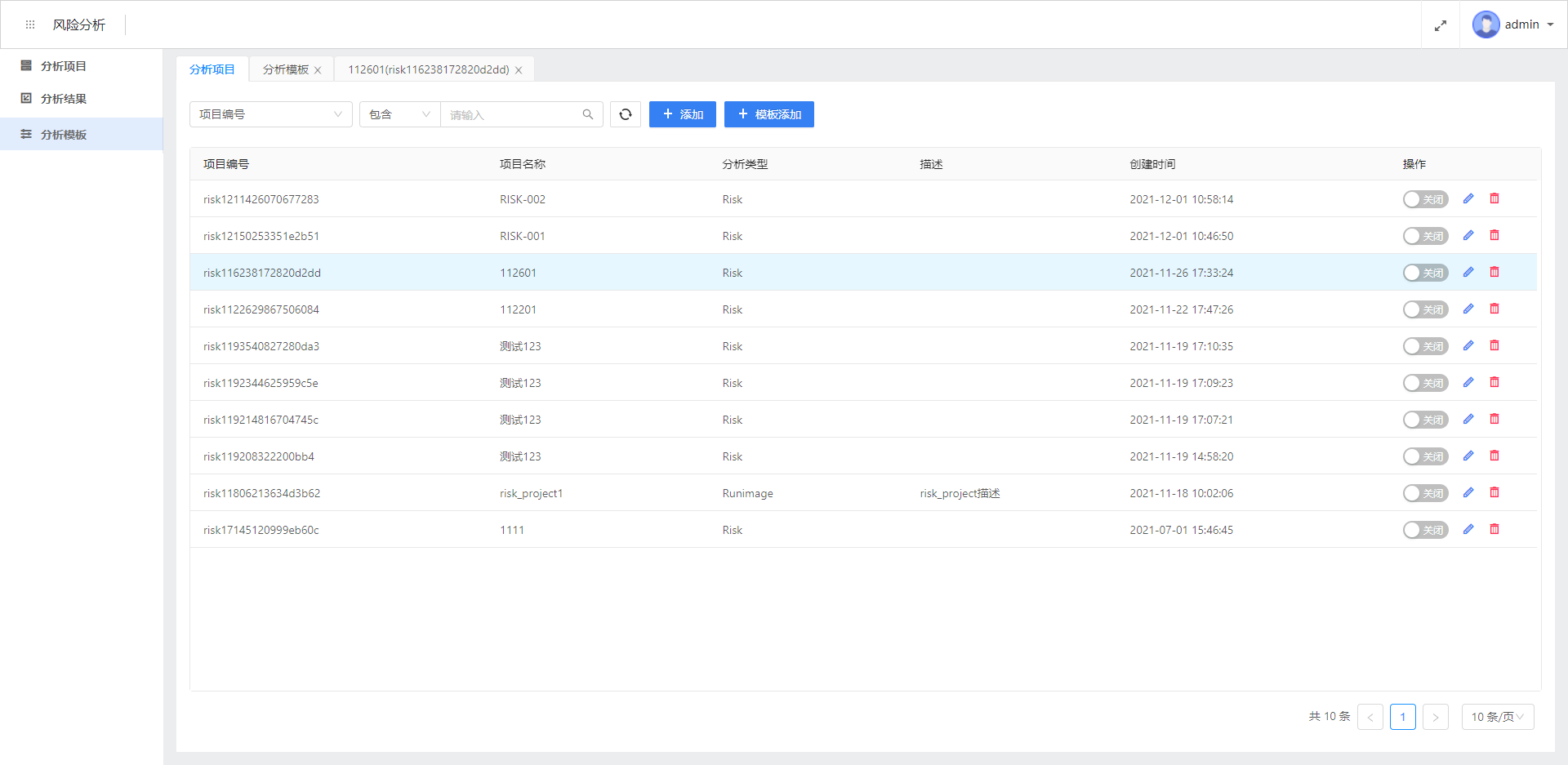
项目管理界面,可以在这个界面进行增删改查的管理,同时还可以管理项目的启停。可以点击添加按钮添加项目,也可以点击某一个项目名称,编辑这个项目的详细配置。
具体怎么配置、修改一个项目,将在下文详细介绍,这里不再赘述。
本界面还有分析对象,描述的是这个项目绑定下的所有对象,结果列表,描述的是本项目下的所有计算结果。
分析模板
 本界面可以查看、编辑风险分析的分析模板,模板用于快速创建、绑定风险分析项目。
本界面可以查看、编辑风险分析的分析模板,模板用于快速创建、绑定风险分析项目。
项目配置

项目名称:项目名称要求不能重复,其具体名称可以从实际需要和便利性出发,填写项目名称。
class名称:根据需要选择class名称,目前风险分析有以下class:
| class中文名 | Class英文名 | 具体功能 |
|---|---|---|
| 风险分析 | Risk | 分析风险对象出现某风险的概率有多大 |
分析计算周期:可选项有:
分钟、小时、其他等等,其他的含义为秒,可以根据需要自行填写,填写范围是从0-999。限定映射表:此处可以关联MixIOT中所有已有的映射表,如果选择
限定映射表,根据要分析的对象,在映射表标识选择相应的映射表。如果选择不限定映射表,那么在对象ID中,直接选择对象。分析计算对象:分析对象有
限定和不限定两个选项。如果选择限定对象,可以接下来选择对象,表示计算这个映射表项目下的一个或者几个对象。如果选择不限定对象,那么就会针对这个映射表,每次计算都动态获取映射表下的所有对象,并分析每个对象下的选定数据偏离水平:如果选择
自定义偏离水平,则根据实际情况,制定具体风险水平的界定5个等级,并将5个等级对应的数字按列表的方式填写,按上面的例子,就是:[0.01,0.2,0.5,0.6,1],分别是无风险,低风险,中风险,高风险和超高风险。如果选择计算条件风险值,那么则填写系统默认风险值,为:[0.2,0.4,0.6,0.8,1]条件风险概率:这里是根据实际情况的历史数据,填写威胁事件的条件概率。条件概率要按照事件来分类,并确认每个参数是属于哪个威胁的。如果选择
给定条件风险值,那么通过各种方式获取到条件概率以后,按照Json的格式,在贝叶斯列表中,写具体的条件风险概率。例如上面的B1、B2、B3三个威胁事件,就填写:
{"B1":0.5,"B2":0.7,"B3":0.9}
如果选在了默认条件风险值,那么系统则默认风险概率为各个事件的概率为0.5,按上面的例子就是:{"B1":0.5,"B2":0.5,"B3":0.5}。
- 计算结果初始化:在我们建立好项目,由于某些原因,又要对项目进行修改时,我们可以选择使用这个参数。在风险分析项目中,有2个历史值一直在计算中滚动更新,一个是风险水平涉及到的马尔科夫矩阵,一个是条件风险概率涉及到的贝叶斯列表。如果选择
继续计算,那么重新启动项目时,会继续用这两个值继续计算。如果选择从头计算,那么就根据修改后的项目的风险水平/偏离水平、风险偏离概率/条件风险概率进行重新计算。也就是说,如果修改了以上两个参数,但是没有选择从头计算,那么修改的参数就不会生效。
脚本规范
二维Json数组
首先,脚本必须为Json格式,否则无法创建项目。每一行为一个分析变量,可以同时存在多行。格式如下:
[
["FV", "Label_En", "Label_Cn", "Weight", "Scale", "Normal", "Tag", "Qmin", "Qmax"]
]
脚本示例如下:
[
["S01", "Label_En", "Label_Cn", 1, 0.3, "", "X", -5, 5],
["S02", "Label_En", "Label_Cn", 1, 0.3, "", "X", -5, 5],
["S03", "Label_En", "Label_Cn", 1, 0.3, "", "X", -5, 5],
["S13", "Label_En", "Label_Cn", 1, 0.2, "", "X", -5, 5],
["S14", "Label_En", "Label_Cn", 1, 0.2, "", "X", -5, 5],
["S15", "Label_En", "Label_Cn", 1, 0.2, "", "Y", -5, 5],
["S77", "Label_En", "Label_Cn", 1, 0.14, "", "Y", -5, 5],
["S78", "Label_En", "Label_Cn", 1, 0.1, "", "Y", -5, 5]
]
填写要求
一行有9个字段,在算法计算的时候使用。
| 字段 | 含义 | 备注 |
|---|---|---|
| FV | 分析参数标识 | 对应映射表的参数 |
| Label_En | 英文标签 | 变量英文描述说明,可填"" |
| Label_Cn | 中文标签 | 变量中文描述说明,可填"" |
| Weight | 参数权重 | 填写本参数的重要性占比权重 |
| Scale | 参数比例 | 填写本参数的数值大小缩放比例 |
| Normal | 参数标准值 | 填写本参数的理想值或标准值,本block不需要,可填"" |
| Tag | 参数标签 | 填写本参数的相关的威胁标签,必填,且与条件风险概率填写对应威胁 |
| Qmin | 参数最小值 | 填写本参数的风险最小值,必填 |
| Qmax | 参数最大值 | 填写本参数风险的最大值,必填 |
脚本中必填的列是:FV、Weight、Scale,并且Weight和Scale必须是数字,Tag可填可不填,填写的话将会起到过滤的作用,保留所有等于该值的数据,其余项用""填空,下面我们逐一介绍。
FV对应的就是对象参数。对象,就是MIXIOT系统中相对应的设备。在建立对象的时候,还要绑定相应的映射表,这里的FV,就对应着相应映射表中的参数。按照我们上文说明的规则选择、填写脚本中第一列的FV,选择了多少个FV,本脚本就有多少行。
Weight,就是上文提到的参数权重,填写的原则就是,谁更重要填写的权重就更大,谁不重要填写的就偏小,建议权重的填写范围在0~1之间。对于权重的填写,其实是没有标准答案的,第一次填写,可以先暂定一个值,计算出结果以后,有必要再进行调试。
Scale,就是参数比例。在实际设备数据中,有可能某些参数范围在0~1之间,比如说压力,有些参数范围是在0~1200,比如说用电量,他们的数据相对大小非常大。假如压力从0上升到1,已经是非常大的变化,但是对于转数,从999到1000,实际上是一个非常平稳的正常波动。
基于这种数据量纲的问题,我们就使用Scale来规避这种问题,对参数数据进行缩放。假如我们想把上面的两个参数缩放到10,那在压力参数的Scale中填写10÷1=10,在转速参数的Scale中填写10÷1000=0.01。经过缩放,两个参数的范围都规整到了0~10中。
Tag,就是填写参数和威胁的对应关系。根据前面确定的威胁事件,把每个参数分类,确定每个参数是属于哪个威胁事件。例如上图的实例,就说明"S01","S02","S03","S13","S14",这几个参数属于X威胁,"S15","S77","S78"三个参数属于Y威胁。
Qmin,就是这个风险参数的最小值,超过这个最小值,将会发生风险。
Qmax,就是这个风险参数的最大值,超过这个最大值,将会发生风险。