指数分析计算
使用手册
[TOC]
简介
指数分析计算,顾名思义,就是围绕指数进行的一系列分析。那么,我们首先从指数入手。
要理解指数,我们可以类比“上证指数”。上证指数,就是以上海证券交易所上市的公司的股票作为样本,以某个权数(发行量)为权重,加权平均得出的一个指数。有了上证指数,我们要了解上证市场,不需要一个个公司研究,只需要关注一个上证指数就可以了。那么INDASS的指数分析,样本就是这个设备的所有参数,或者按MIXIOT的概念来说,是一个对象的所有参数,权重,就是这些参数的相对重要性。
但是,一个对象可能涉及到成百上千个参数,真的要全部考虑吗?我们还是类比上证指数,上证指数分为上证综指、上证50指数、上证180指数等等,上证综指,可能就是考虑了所有公司的所有股票,但是上证50指数,就是选择了规模大、流动性好的最具代表性的50只股票作为样本了。在指数分析中,我们也可以明确我们的重点,选择相关的重点参数进行分析。例如想研究工业对象的“能耗指数”,就选择对象能耗有关的参数;想研究工业对象的“排放指数”,就选择跟排放的强相关的参数。同时,还要确定权重,这其实就是一个参数筛选的过程。一开始从众多参数中,选择跟我们研究指数相关的参数,进一步的,在这些参数中,再比较出相对的重要性,通过权重表达出来。最终,通过指数分析的计算公式计算出指数值。
适用范围(应用场景)
指数普遍适用于所有工业对象的设备数据,他其实是一个“浓缩值”,是在我们经过计算以后,希望可以”窥一斑而知全豹“。
使用限制
指数分析仅能运行在服务器中,数据源目前仅支持实时数据。
主要功能
指数分析计算的主要功能,就是通过选择的对象和参数, 计算出指数值以及其余相关结果。
基本概念
指数,实际研究的其实是时序数据标量化的问题。所谓的时序数据,就是适配器每隔一段时间,采集的设备参数数据。那么,指数将多个参数的时序数据浓缩成一个值,又该如何使用呢?接下来就介绍一下指数变化率。
指数差值,是当前期的指数值,减去上一期的指数值得出的结果。当我们计算出指数的一个值的时候,其实是无法知道什么问题的,类比上证指数,我们也不能从上证指数3500获取到什么信息。但是,假如我们知道,昨天的上证指数是3490,今天的上证指数是3500,那么我们就可以知道,今天指数涨了10个点。
所以,同样的设备指数,我们也无法从一个值获取什么具体的信息,但是,如果把一段时间的指数都拿出来做分析,我们就可以看到相应的规律,也能通过比较,得到一些推论。这就是指数差值的用处,他可以看出当期和前一期的指数变化值。
指数变化率,就是当期的指数差值除以当期的指数值,结果是一个环比增长率,只不过由于方便后续处理,这个的结果并没有乘以100%。这个值也是从”变化“的侧面来表达指数的变化。简单来说,当变化率为正时,本期的指数呈增长趋势,当变化率为负时,本期的指数呈下降趋势。
指数变化速度,就是当前期的指数变化率除以周期时长。为了统一,这个周期全部转化为秒,也就是说,这个指数变化速度,展示的是指数的每秒变化程度。 那么,我们由指数变化速度能知道什么呢?假设是一辆匀速行驶的车,如果我们知道了它的速度,又知道了它的现在的位置,那么我们就能知道下一秒在什么地方。
指数变化速度也是一样的用法,当我们获取到指数变化速度以后,基本上就能知道下一期的指数会在什么样的范围。或者浅显来说,不看指数变化速度的正负号,就代表了下一期指数的波动范围,指数变化速度的正负号,就代表了下一期的指数到底是增加还是降低。
上面的指数变化速度,是反应了整个对象的指数变化趋势,进一步的,有时候我们更想知道到底是哪个参数的变化导致了指数的变化。这个各参数的指数变化速度,就是反应每个参数的变化速度的结果参数。 各参数的变化速度,其实也是用对比看出结果。相对来说,如果其中一个时刻中的某参数变化速度特别大,那么就可以值得研究,和实际情况相对照,是不是设备的情况发生了什么异常。
指数变化加速度,就是指数的变化速度的变化率,它能够比速度更敏感的反应指数的变化情况,也能大概估计下一期的指数值的所处范围。 这里的加速度,也可以类比行驶的汽车,汽车在匀速行驶时,加速度是0,当加速度变化时,我们就能肯定,速度肯定是变化的,下一秒汽车所走的距离,肯定与匀速行驶时的距离有所不同。 指数变化的加速度,为了更加统一,也是每秒的指数加速度。
各参数的指数变化加速度,类比概念五,也是反映每个参数的数值变化的加速度。一般来说,如果指数的变化加速度突然变大,我们进一步想看看是哪些参数发生了异常,那就再研究各个参数的变化加速度。同样的,也是考虑他的相对变化,如果某个参数的变化加速度突然变动,那就值得引起我们的注意,考虑这个数据变化背后的实际情况。
界面说明
指数分析计算一共有3个界面,接下来我们分别展示:
项目管理
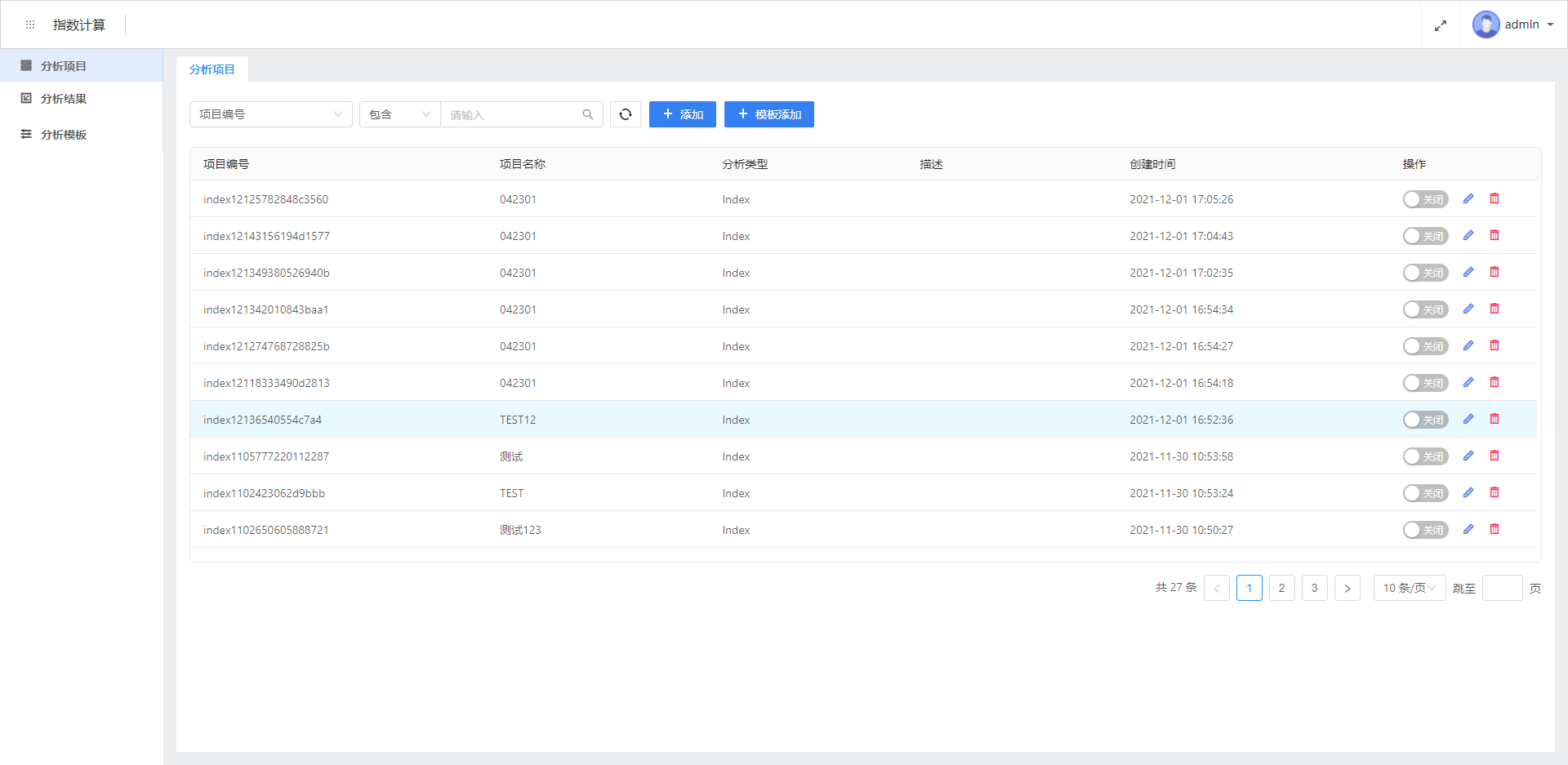
项目管理界面,可以在这个界面进行增删改查的管理,同时还可以管理项目的启停。可以点击添加按钮添加项目,也可以点击某一个项目名称,编辑这个项目的详细问题。
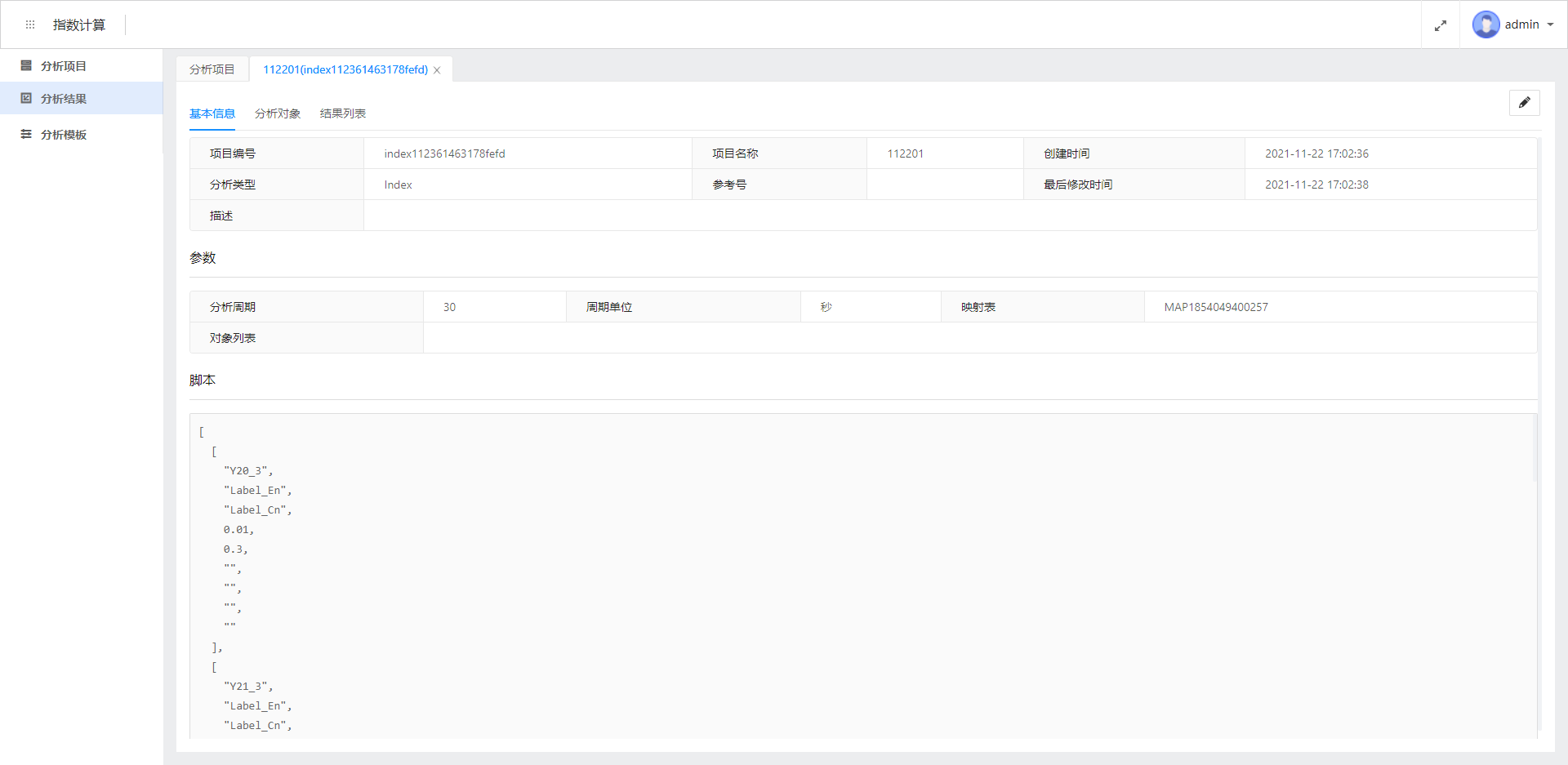
具体怎么配置、修改一个项目,将在下文详细介绍,这里不再赘述。
本界面还有分析对象,描述的是这个项目绑定下的所有对象,结果列表,描述的是本项目下的所有计算结果。
分析模板
 本界面可以查看、编辑指数分析的分析模板,模板用于快速创建项目。
本界面可以查看、编辑指数分析的分析模板,模板用于快速创建项目。
配置方法
添加项目

项目名称:项目名称要求不能重复,其具体名称可以从实际需要和便利性出发,填写项目名称
class名称:根据需要选择class名称,目前指数分析有以下class:
| class中文名 | Class英文名 | 具体功能 |
|---|---|---|
| 指数分析计算 | Index | 标准对象运行指数分析计算 |
- 分析计算周期:可选项有:
分钟、小时、其他等等,其他的含义为秒,可以根据需要自行填写,填写范围是从0-999。 - 限定映射表:此处可以关联MixIOT中所有已有的映射表,如果选择
限定映射表,根据要分析的对象,在映射表标识选择相应的映射表。如果选择不限定映射表,那么在对象ID中,直接选择对象。 - 分析计算对象:分析对象有
限定和不限定两个选项。如果选择限定对象,可以接下来选择对象,表示计算这个映射表项目下的一个或者几个对象。如果选择不限定对象,那么就会针对这个映射表,每次计算都动态获取映射表下的所有对象,并分析每个对象下的选定数据。
脚本规范
二维Json数组
首先,脚本必须为Json格式,否则无法创建项目。每一行为一个分析变量,可以同时存在多行。格式如下:
[
["FV", "Label_En", "Label_Cn", "Weight", "Scale", "Normal", "Tag", "Qmin", "Qmax"]
]
脚本示例如下:
[
["S01", "Label_En", "Label_Cn", 1, 0.3, "", "X", -5, 5],
["S02", "Label_En", "Label_Cn", 1, 0.3, "", "X", -5, 5],
["S03", "Label_En", "Label_Cn", 1, 0.3, "", "X", -5, 5],
["S13", "Label_En", "Label_Cn", 1, 0.2, "", "X", -5, 5],
["S14", "Label_En", "Label_Cn", 1, 0.2, "", "X", -5, 5],
["S15", "Label_En", "Label_Cn", 1, 0.2, "", "Y", -5, 5],
["S77", "Label_En", "Label_Cn",1, 0.14, "", "Y", -5, 5],
["S78", "Label_En", "Label_Cn", 1, 0.1, "", "Y", -5, 5]
]
填写要求
一行有9个字段,在算法计算的时候使用。
| 字段 | 含义 | 备注 |
|---|---|---|
| FV | 分析参数标识 | 对应映射表的参数 |
| Label_En | 英文标签 | 变量英文描述说明,可填"" |
| Label_Cn | 中文标签 | 变量中文描述说明,可填"" |
| Weight | 参数权重 | 填写本参数的重要性占比权重 |
| Scale | 参数比例 | 填写本参数的数值大小缩放比例 |
| Normal | 参数标准值 | 填写本参数的理想值或标准值,本block不需要,可填"" |
| Tag | 参数标签 | 填写本参数的标签 |
| Qmin | 参数最小值 | 填写本参数的最小值,本block不需要,可填"" |
| Qmax | 参数最大值 | 填写本参数的最大值,本block不需要,可填"" |
脚本中必填的列是:FV、Weight、Scale,并且Weight和Scale必须是数字,Tag可填可不填,填写的话将会起到过滤的作用,保留所有等于该值的数据,其余项用""填空,下面我们逐一介绍。
FV对应的就是对象参数。对象,就是MIXIOT系统中相对应的设备。在建立对象的时候,还要绑定相应的映射表,这里的FV,就对应着相应映射表中的参数。按照我们上文说明的规则选择、填写脚本中第一列的FV,选择了多少个FV,本脚本就有多少行。
Weight,就是上文提到的参数权重,填写的原则就是,谁更重要填写的权重就更大,谁不重要填写的就偏小,建议权重的填写范围在0~1之间。对于权重的填写,其实是没有标准答案的,第一次填写,可以先暂定一个值,计算出结果以后,有必要再进行调试。
Scale,就是参数比例。在实际设备数据中,有可能某些参数范围在0~1之间,比如说压力,有些参数范围是在0~1200,比如说用电量,他们的数据相对大小非常大。假如压力从0上升到1,已经是非常大的变化,但是对于转数,从999到1000,实际上是一个非常平稳的正常波动。
基于这种数据量纲的问题,我们就使用Scale来规避这种问题,对参数数据进行缩放。假如我们想把上面的两个参数缩放到10,那在压力参数的Scale中填写10÷1=10,在转速参数的Scale中填写10÷1000=0.01。经过缩放,两个参数的范围都规整到了0~10中。
Tag,就是标签。在我们实际计算中,例如我们只考虑设备开机的情况的指数值,关机时不需要计算指数值,那么我们就可以增加一个开关机的FV,假设开机时数据为1,关机时数据为0。那么我们在Tag中填写1,过滤掉所有开关机量为0的数据,得出的结果就全部是开机时的指数计算结果。
应用实例
应用简述
在锅炉的运行过程中,我们重要关注的就是这个锅炉的能效分析情况,因此,我们可以使用指数分析,建立锅炉的能效指数,从能效指数观测锅炉的整体运行情况。
解决方案
接下来的例子,就是根据某型号锅炉的能效数据,按照每分钟计算一次的频率,计算得出结果,并进行分析。
首先我们先看一下能效参数的部分数据片段:
| R | S01 | S05 | S06 | S07 | S08 | S09 | S10 | S11 | S12 | S13 | S14 | S15 | S19 | S66 | S69 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 97.7 | 0.88 | 212.6 | 130.5 | 85 | 85.9 | 87.6 | 58.8 | 63.7 | 64 | 120 | 45.5 | 76.9 | 3.9 | 3.78 | 301.7 |
| 97.6 | 0.89 | 213.4 | 139.3 | 88.1 | 83 | 96.9 | 59.2 | 64.5 | 64.9 | 71.6 | 46.2 | 78.8 | 3.8 | 3.89 | 291.55 |
| 97.6 | 0.89 | 213.4 | 139.3 | 88.1 | 83 | 96.9 | 59.2 | 64.5 | 64.9 | 71.6 | 46.2 | 78.8 | 3.8 | 3.89 | 291.55 |
| 97.6 | 0.91 | 214.3 | 149.7 | 90.2 | 107.7 | 110.8 | 59.7 | 65.7 | 66 | 86.5 | 46.5 | 81 | 3.7 | 4.48 | 290.33 |
| 97.6 | 0.91 | 214.3 | 149.7 | 90.2 | 107.7 | 110.8 | 59.7 | 65.7 | 66 | 86.5 | 46.5 | 81 | 3.7 | 4.48 | 290.33 |
| 97.6 | 0.94 | 214.7 | 148.7 | 89 | 87.2 | 124.7 | 60.1 | 66 | 66.2 | 116.5 | 46.2 | 77 | 3.8 | 5.08 | 287.88 |
| 97.6 | 0.94 | 214.7 | 148.7 | 89 | 87.2 | 124.7 | 60.1 | 66 | 66.2 | 116.5 | 46.2 | 77 | 3.8 | 5.08 | 287.88 |
| 97.6 | 0.95 | 214.4 | 142.9 | 87.9 | 86.3 | 125.8 | 60.6 | 66.3 | 66.6 | 120 | 46.2 | 78.7 | 3.8 | 4.28 | 289 |
| 97.6 | 0.95 | 214.4 | 142.9 | 87.9 | 86.3 | 125.8 | 60.6 | 66.3 | 66.6 | 120 | 46.2 | 78.7 | 3.8 | 4.11 | 290.34 |
| 97.7 | 0.94 | 214 | 136.7 | 86 | 96.6 | 104.7 | 60.9 | 66.2 | 66.5 | 94.2 | 46.2 | 80 | 3.8 | 4.11 | 290.34 |
| 97.7 | 0.92 | 213.7 | 130.9 | 85.2 | 97 | 103 | 61.3 | 66.1 | 66.4 | 99.7 | 46.1 | 78.9 | 4 | 3.63 | 290.48 |
| 97.7 | 0.92 | 213.7 | 130.9 | 85.2 | 97 | 103 | 61.3 | 66.1 | 66.4 | 99.7 | 46.1 | 78.9 | 4 | 3.8 | 268.66 |
| 97.6 | 0.98 | 214 | 133.6 | 87.5 | 65.3 | 104.7 | 61.7 | 66.5 | 66.8 | 114.9 | 46.4 | 72.2 | 4.2 | 3.8 | 268.66 |
| 97.6 | 0.98 | 214 | 133.6 | 87.5 | 65.3 | 104.7 | 61.7 | 66.5 | 66.8 | 114.9 | 46.4 | 72.2 | 4.2 | 4.1 | 272.53 |
| 97.5 | 0.96 | 214.6 | 140.9 | 89.4 | 70.4 | 120.1 | 62.3 | 67.5 | 67.8 | 71.3 | 46.7 | 74.5 | 4 | 4.1 | 272.53 |
| 97.5 | 0.96 | 214.6 | 140.9 | 89.4 | 70.4 | 120.1 | 62.3 | 67.5 | 67.8 | 71.3 | 46.7 | 74.5 | 4 | 4.1 | 272.53 |
| 97.5 | 0.95 | 214.7 | 144.4 | 90.4 | 96 | 123.7 | 62.7 | 68.3 | 68.6 | 63.1 | 47.4 | 90.1 | 3.7 | 3.81 | 284.04 |
| 97.5 | 0.95 | 214.7 | 144.4 | 90.4 | 96 | 123.7 | 62.7 | 68.3 | 68.6 | 63.1 | 47.4 | 90.1 | 3.7 | 3.81 | 284.04 |
| 97.6 | 0.95 | 214.7 | 143.9 | 89.8 | 104.3 | 127.4 | 63.2 | 68.7 | 69 | 123.8 | 47.4 | 89.7 | 3.7 | 4.35 | 292.79 |
| 97.6 | 0.95 | 214.7 | 143.9 | 89.8 | 104.3 | 127.4 | 63.2 | 68.7 | 69 | 123.8 | 47.4 | 89.7 | 3.7 | 4.35 | 292.79 |
案例分析
编写INDASS的项目脚本,并不是唯一的。每个脚本,只有合适和不合适的区别,并没有绝对的对错之分,我们要根据实际的使用方式,调节好合适的脚本。在这个案例中,就有2个脚本来说明这个问题。
在评估锅炉的能效指数时,重要的参数有以下参数,这个就是第一阶段的脚本:
[
["R", "", "热效率", 1, 0.01, "", "", "", ""],
["S01", "", "锅炉压力", 1, 1, "", "", "", ""],
["S05", "", "本体排烟温度", 1, 0.05, "", "", "", ""],
["S06", "", "节能排烟温度", 1, 0.02, "", "", "", ""],
["S07", "", "排烟温度", 1, 0.01, "", "", "", ""],
["S08", "", "节能进水温度", 1, 0.01, "", "", "", ""],
["S09", "", "节能出水温度", 1, 0.01, "", "", "", ""],
["S10", "", "冷凝进水温度", 1, 0.02, "", "", "", ""],
["S11", "", "冷凝出水温度", 1, 0.02, "", "", "", ""],
["S12", "", "空气加热器进水温度", 1, 0.02, "", "", "", ""],
["S13", "", "空气加热器出水温度", 1, 0.02, "", "", "", ""],
["S14", "", "空气加热器进气温度", 1, 0.02, "", "", "", ""],
["S15", "", "空气加热器出气温度", 1, 0.01, "", "", "", ""],
["S19", "", "烟气氧含量", 1, 0.25, "", "", "", ""],
["S66", "", "蒸汽瞬时流量", 1, 0.25, "", "", "", ""],
["S69", "", "燃气瞬时流量", 1, 0.005, "", "", "", ""]
]
这些参数,是和能效部分相关紧密的参数,所以在考虑锅炉的能效的时候,首先把这些跟能效相关性强的参数全部选择出来。第一列就是参数在映射表中的FV,第二列是英文名,第三列是中文名,这两列仅仅是帮助我们明确、了解参数名字,如果不需要,可以填空""。
第四列和第五列是权重和比例。在考虑能效指数的时候,总体来说有三类数据,一类是压力数据,这些数据范围在0~1波动,另一类是温度数据和燃气流量,波动范围在0~300左右波动,另外就是效率、氧含量,这些是百分数,大小在0~100波动。为了让指数的数据比较好看、好分析,我们希望把指数值控制在比较小的范围内,所以在比例中填写相应的数值,把每个数据都缩放到0-1之间。
举个例子,比如热效率的范围是0~100,比例数就填写1/100=0.01,再比如锅炉压力的范围是0~1,不需要做缩放,所以比例数写1/1=1,蒸汽瞬时流量大概在4附近,比例数填写1/4=0.25,以此类推。
在考虑权重的时候,我们暂且觉得这些参数都是一样重要的,所以在第三列的权重的部分全部填写1,看看结果再做决定。
至此,第一阶段的脚本完成了,我们可以保存项目后运行项目。看看部分数据结果。
| 指数值 | 指数差值 | 指数差值加速度 | 指数变化率 | 指数差值速度 | |
|---|---|---|---|---|---|
| 5:17:30 | 7111.22 | 574.78 | 0 | 0.09 | 1.6 |
| 5:18:30 | 7553.13 | 441.91 | 0 | 0.06 | 1.23 |
| 5:19:30 | 8022.35 | 469.22 | 0 | 0.06 | 1.3 |
| 5:20:30 | 8333.23 | 310.88 | 0 | 0.04 | 0.86 |
| 5:21:30 | 8591.79 | 258.56 | 0 | 0.03 | 0.72 |
| 5:22:30 | 8412.83 | -178.96 | 0 | -0.02 | -0.5 |
| 5:23:30 | 8693.97 | 281.14 | 0 | 0.03 | 0.78 |
我们看到,index_value这个值特别大,导致明明设备没有特别大的波动,但是指数值变化非常大,不是非常利于分析,出于这个目的,我们可以进一步调节上面脚本的权重值。我们暂且还是觉得每个参数的重要性都相等,这样每个参数的权重值都统一缩小100倍,填写0.01,第二个脚本如下:
[
["R", "", "热效率", 0.01, 0.01, "", "", "", ""],
["S01", "", "锅炉压力", 0.01, 1, "", "", "", ""],
["S05", "", "本体排烟温度", 0.01, 0.05, "", "", "", ""],
["S06", "", "节能排烟温度", 0.01, 0.02, "", "", "", ""],
["S07", "", "排烟温度", 0.01, 0.01, "", "", "", ""],
["S08", "", "节能进水温度", 0.01, 0.01, "", "", "", ""],
["S09", "", "节能出水温度", 0.01, 0.01, "", "", "", ""],
["S10", "", "冷凝进水温度", 0.01, 0.02, "", "", "", ""],
["S11", "", "冷凝出水温度", 0.01, 0.02, "", "", "", ""],
["S12", "", "空气加热器进水温度", 0.01, 0.02, "", "", "", ""],
["S13", "", "空气加热器出水温度", 0.01, 0.02, "", "", "", ""],
["S14", "", "空气加热器进气温度", 0.01, 0.02, "", "", "", ""],
["S15", "", "空气加热器出气温度", 0.01, 0.01, "", "", "", ""],
["S19", "", "烟气氧含量", 0.01, 0.25, "", "", "", ""],
["S66", "", "蒸汽瞬时流量", 0.01, 0.25, "", "", "", ""],
["S69", "", "燃气瞬时流量", 0.01, 0.005, "", "", "", ""]
]
保存项目后,我们再次启动项目,可以看到如下部分结果:
| 指数值 | 指数差值 | 指数差值加速度 | 指数变化率 | 指数差值速度 | |
|---|---|---|---|---|---|
| 5:17:30 | 71.12 | 5.79 | 0 | 0.09 | 0.02 |
| 5:18:30 | 75.09 | 3.97 | 0 | 0.06 | 0.01 |
| 5:19:30 | 80.2 | 5.11 | 0 | 0.07 | 0.01 |
| 5:20:30 | 83.35 | 3.15 | 0 | 0.04 | 0.01 |
| 5:21:30 | 85.43 | 2.08 | 0 | 0.02 | 0.01 |
| 5:22:30 | 84.19 | -1.24 | 0 | -0.01 | 0 |
| 5:23:30 | 86.5 | 2.31 | 0 | 0.03 | 0.01 |
这样的结果就比较好理解,在设备平稳波动的时候,指数也波动较小,证明第二个脚本从这个角度来说,比第一个脚本比较好。
但是如果考虑各参数的指数变化速度和各参数的指数变化加速度这两个结果:
脚本一结果:
| 各参数的指数变化速度 | 各参数的指数变化加速度 | |
|---|---|---|
| 5:17:30 | {"R": 0.95, "S01": -0.02, "S05": 1.74, "S06": 0.17, "S07": 0.11, "S08": 0.01, "S09": -0.0, "S10": -0.02, "S11": 0.11, "S12": 0.13, "S13": 0.01, "S14": 0.19, "S15": 0.06, "S19": -2.0, "S66": 0.14, "S69": 0.02} | {"R": 0.0, "S01": -0.0, "S05": 0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": -0.0, "S11": -0.0, "S12": -0.0, "S13": 0.0, "S14": 0.0, "S15": 0.0, "S19": -0.0, "S66": 0.0, "S69": 0.0} |
| 5:18:30 | {"R": 0.03, "S01": 0.08, "S05": 1.75, "S06": 0.37, "S07": 0.07, "S08": 0.02, "S09": 0.03, "S10": -0.02, "S11": 0.02, "S12": 0.02, "S13": 0.01, "S14": -0.01, "S15": 0.06, "S19": -2.6, "S66": -0.05, "S69": 1.44} | {"R": -0.0, "S01": 0.0, "S05": 0.0, "S06": 0.0, "S07": -0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": -0.0, "S12": -0.0, "S13": 0.0, "S14": -0.0, "S15": 0.0, "S19": -0.0, "S66": -0.0, "S69": 0.0} |
| 5:19:30 | {"R": -0.0, "S01": 0.09, "S05": 0.88, "S06": 0.41, "S07": 0.08, "S08": 0.04, "S09": 0.04, "S10": -0.02, "S11": 0.01, "S12": 0.01, "S13": 0.01, "S14": 0.0, "S15": 0.05, "S19": -0.3, "S66": -0.0, "S69": 0.01} | {"R": -0.0, "S01": 0.0, "S05": -0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": -0.0, "S12": -0.0, "S13": 0.0, "S14": 0.0, "S15": -0.0, "S19": 0.0, "S66": 0.0, "S69": -0.0} |
| 5:20:30 | {"R": -0.0, "S01": 0.09, "S05": 0.38, "S06": 0.26, "S07": 0.05, "S08": 0.03, "S09": 0.04, "S10": -0.0, "S11": 0.0, "S12": 0.0, "S13": 0.01, "S14": 0.01, "S15": 0.03, "S19": -0.05, "S66": 0.01, "S69": 0.0} | {"R": 0.0, "S01": 0.0, "S05": -0.0, "S06": -0.0, "S07": -0.0, "S08": -0.0, "S09": 0.0, "S10": 0.0, "S11": -0.0, "S12": -0.0, "S13": 0.0, "S14": 0.0, "S15": -0.0, "S19": 0.0, "S66": 0.0, "S69": -0.0} |
| 5:21:30 | {"R": -0.0, "S01": 0.07, "S05": 0.28, "S06": 0.15, "S07": 0.02, "S08": 0.02, "S09": 0.19, "S10": 0.0, "S11": 0.01, "S12": 0.01, "S13": 0.0, "S14": 0.0, "S15": 0.01, "S19": -0.03, "S66": -0.03, "S69": 0.0} | {"R": 0.0, "S01": -0.0, "S05": -0.0, "S06": -0.0, "S07": -0.0, "S08": -0.0, "S09": 0.0, "S10": 0.0, "S11": 0.0, "S12": 0.0, "S13": -0.0, "S14": -0.0, "S15": -0.0, "S19": 0.0, "S66": -0.0, "S69": 0.0} |
| 5:22:30 | {"R": -0.93, "S01": 0.09, "S05": -0.04, "S06": 0.06, "S07": 0.01, "S08": 0.25, "S09": 0.13, "S10": 0.0, "S11": -0.01, "S12": -0.01, "S13": -0.0, "S14": 0.02, "S15": 0.02, "S19": 0.55, "S66": 0.04, "S69": -0.68} | {"R": -0.0, "S01": 0.0, "S05": -0.0, "S06": -0.0, "S07": -0.0, "S08": 0.0, "S09": -0.0, "S10": 0.0, "S11": -0.0, "S12": -0.0, "S13": -0.0, "S14": 0.0, "S15": 0.0, "S19": 0.0, "S66": 0.0, "S69": -0.0} |
| 5:23:30 | {"R": -0.05, "S01": 0.0, "S05": -0.92, "S06": -0.15, "S07": -0.05, "S08": 0.15, "S09": 0.01, "S10": -0.0, "S11": -0.02, "S12": -0.02, "S13": -0.0, "S14": -0.03, "S15": 0.01, "S19": 2.58, "S66": -0.06, "S69": -0.67} | {"R": 0.0, "S01": -0.0, "S05": -0.0, "S06": -0.0, "S07": -0.0, "S08": -0.0, "S09": -0.0, "S10": -0.0, "S11": -0.0, "S12": -0.0, "S13": 0.0, "S14": -0.0, "S15": -0.0, "S19": 0.0, "S66": -0.0, "S69": 0.0} |
脚本二结果:
| 各参数的指数变化速度 | 各参数的指数变化加速度 | |
|---|---|---|
| 5:17:30 | {"R": 0.01, "S01": -0.0, "S05": 0.02, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": -0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": 0.0, "S15": 0.0, "S19": -0.02, "S66": 0.0, "S69": 0.0} | {"R": 0.0, "S01": -0.0, "S05": 0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": -0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": 0.0, "S15": 0.0, "S19": -0.0, "S66": 0.0, "S69": 0.0} |
| 5:18:30 | {"R": 0.0, "S01": 0.0, "S05": 0.02, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": -0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": -0.0, "S15": 0.0, "S19": -0.03, "S66": -0.0, "S69": 0.01} | {"R": -0.0, "S01": 0.0, "S05": 0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": -0.0, "S15": 0.0, "S19": -0.0, "S66": -0.0, "S69": 0.0} |
| 5:19:30 | {"R": -0.0, "S01": 0.0, "S05": 0.01, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": -0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": 0.0, "S15": 0.0, "S19": -0.0, "S66": -0.0, "S69": 0.0} | {"R": -0.0, "S01": 0.0, "S05": -0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": 0.0, "S15": 0.0, "S19": 0.0, "S66": 0.0, "S69": -0.0} |
| 5:20:30 | {"R": -0.0, "S01": 0.0, "S05": 0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": -0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": 0.0, "S15": 0.0, "S19": -0.0, "S66": 0.0, "S69": 0.0} | {"R": 0.0, "S01": 0.0, "S05": -0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": 0.0, "S15": 0.0, "S19": 0.0, "S66": 0.0, "S69": 0.0} |
| 5:21:30 | {"R": 0.0, "S01": 0.0, "S05": 0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": 0.0, "S15": 0.0, "S19": -0.0, "S66": -0.0, "S69": 0.0} | {"R": 0.0, "S01": 0.0, "S05": 0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": 0.0, "S15": 0.0, "S19": 0.0, "S66": -0.0, "S69": 0.0} |
| 5:22:30 | {"R": -0.01, "S01": 0.0, "S05": 0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": -0.0, "S12": -0.0, "S13": -0.0, "S14": 0.0, "S15": 0.0, "S19": 0.01, "S66": 0.0, "S69": -0.01} | {"R": -0.0, "S01": 0.0, "S05": 0.0, "S06": 0.0, "S07": 0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": -0.0, "S12": -0.0, "S13": -0.0, "S14": 0.0, "S15": 0.0, "S19": 0.0, "S66": 0.0, "S69": -0.0} |
| 5:23:30 | {"R": -0.0, "S01": 0.0, "S05": -0.01, "S06": -0.0, "S07": -0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": -0.0, "S12": -0.0, "S13": -0.0, "S14": -0.0, "S15": 0.0, "S19": 0.02, "S66": -0.0, "S69": -0.01} | {"R": 0.0, "S01": 0.0, "S05": -0.0, "S06": -0.0, "S07": -0.0, "S08": 0.0, "S09": 0.0, "S10": 0.0, "S11": 0.0, "S12": 0.0, "S13": 0.0, "S14": -0.0, "S15": 0.0, "S19": 0.0, "S66": -0.0, "S69": 0.0} |
很明显,由于权重和比例将参数缩放的太小,导致计算的时候,由于保留的小数太小,每个波动都近似于0。从这个角度来说,脚本一又比脚本二更好。在实际情况中,我们活学活用,可以多设计几个脚本,可以让他们同时按照一致的时间间隔运行,在分析的时候,取长补短,各取所需。
我们截取一段时间的指数结果,画出以下曲线:
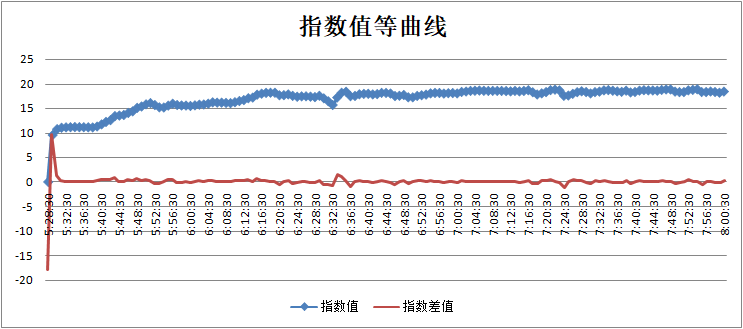
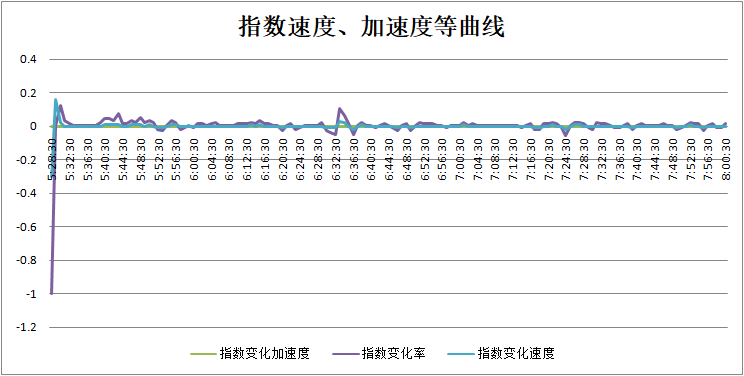
我们可以看出,指数值从0开始增加,可以简单推断出,从五点半到五点三十二可能是一段开机时间,随后锅炉稳定运行,在六点三十二的前后时间内,多个指数参数的结果都有比较明显的波动,对于正常运行的锅炉来说,是不应该出现的。此时我们应该提高警惕,同时对照锅炉实际的运行状态。通过我们后面的验证,发现了六点三十一分时确实发生了锅炉由于S19-烟气氧含量低导致的锅炉报警。
知道了这个情况后,接下来可以设计第三种脚本,专门用于反应烟气含氧量在能效指数,这样,可以提前看出会不会再次发生烟气氧含量低导致的锅炉报警。
[
["R", "", "热效率", 0.01, 0.01, "", "", "", ""],
["S01", "", "锅炉压力", 0.01, 1, "", "", "", ""],
["S05", "", "本体排烟温度", 0.01, 0.05, "", "", "", ""],
["S06", "", "节能排烟温度", 0.01, 0.02, "", "", "", ""],
["S07", "", "排烟温度", 0.01, 0.01, "", "", "", ""],
["S08", "", "节能进水温度", 0.01, 0.01, "", "", "", ""],
["S09", "", "节能出水温度", 0.01, 0.01, "", "", "", ""],
["S10", "", "冷凝进水温度", 0.01, 0.02, "", "", "", ""],
["S11", "", "冷凝出水温度", 0.01, 0.02, "", "", "", ""],
["S12", "", "空气加热器进水温度", 0.01, 0.02, "", "", "", ""],
["S13", "", "空气加热器出水温度", 0.01, 0.02, "", "", "", ""],
["S14", "", "空气加热器进气温度", 0.01, 0.02, "", "", "", ""],
["S15", "", "空气加热器出气温度", 0.01, 0.01, "", "", "", ""],
["S19", "", "烟气氧含量", 1, 0.25, "", "", "", ""],
["S66", "", "蒸汽瞬时流量", 0.01, 0.25, "", "", "", ""],
["S69", "", "燃气瞬时流量", 0.01, 0.005, "", "", "", ""]
]
在这里,我们把烟气氧含量的权重配比改为1,含义就是烟气氧含量对比其余的参数,重要10倍。保存后得出新的结果,可以看出:
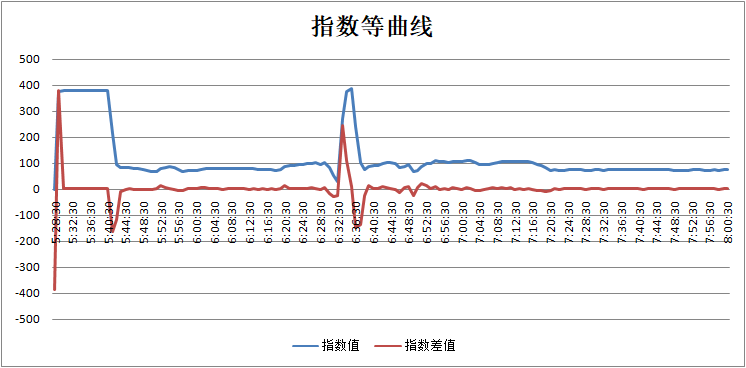

由这两个曲线对比来看,首先,从指数值就可以看出,烟气氧含量在05:40就处于比较低的区间内,到06:28,又在进一步降低,指数的加速度和速度都可以提前看出这一变化。
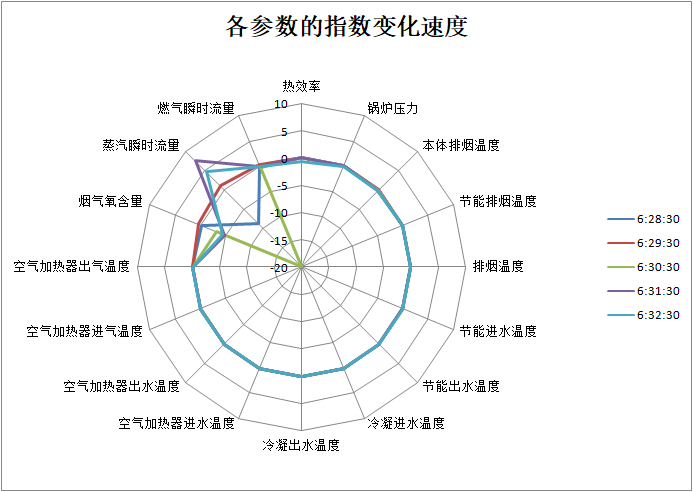
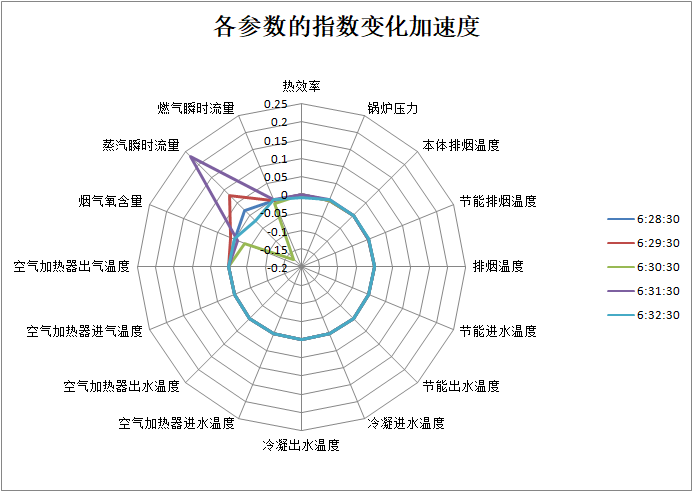
通过各参数的变化速度、加速度,也可以定位具体是哪些参数波动比较大,通过两个雷达图,可以看到烟气氧含量是波动较大的,另一方面,蒸汽的瞬时流量也是波动较大。在对比锅炉的实际情况后,可知因为此时发生的含氧量低的异常导致了锅炉停机,所以导致了无法产生蒸汽,再次开机后,蒸汽重新供应。可以与上图对应上。
本案例对比了3个脚本,各个脚本各有优势,没有绝对的对错之分,接下来可以针对锅炉实际情调节各个参数的权重、比例,也可以针对这些参数做增加和删减等等。无论如何,这些脚本的结果都需要一段时间的运行,观察结果是否能够反映真正的现实,反映设备的实际运行状态。